tldr: Every article ranking for "software testing strategies" lists the same eight strategy types from a 20-year-old syllabus. Those categories were invented when writing a test cost a day of engineer time. In 2026, AI writes a test in a prompt. The canonical framework is pricing the wrong resource. Your strategy should reflect 2026 realities, or you are strategizing for the wrong decade.
The canon is wrong
Open any page-one result for "software testing strategies" in 2026 and you will find the same list. Analytical. Model-based. Methodical. Process-based. Reactive. Regression-averse. Risk-based. Hybrid.
This taxonomy comes from ISTQB syllabus material written around 2005. It was a useful framework then. It priced a real constraint: a human QA engineer sitting at a keyboard, writing test cases by hand, at the speed of a human. Strategy meant deciding which tests that human got to write, because most of the ones you needed would never get written.
That constraint is gone.
An AI agent writes a working end-to-end test in two minutes. An engineer with Cursor writes a unit test in thirty seconds. The bottleneck moved. It is no longer test creation. It is test triage, CI cost, and flake noise. The 2005 canon has nothing to say about any of those.
So when you read a competitor's article telling you to choose between "analytical" and "reactive" testing, they are answering a question nobody on your team has asked since 2019. They are ranked because Google rewards the consensus. The consensus is stale.
This article argues something different. Strategy in 2026 is not a taxonomy of testing types. It is a budget allocation problem. You have a finite amount of engineering attention, a finite CI bill, and a finite tolerance for production bugs. Strategy is how you split those budgets across the failure modes you actually care about. Everything else is theater.
What actually changed: the unit economics of a test
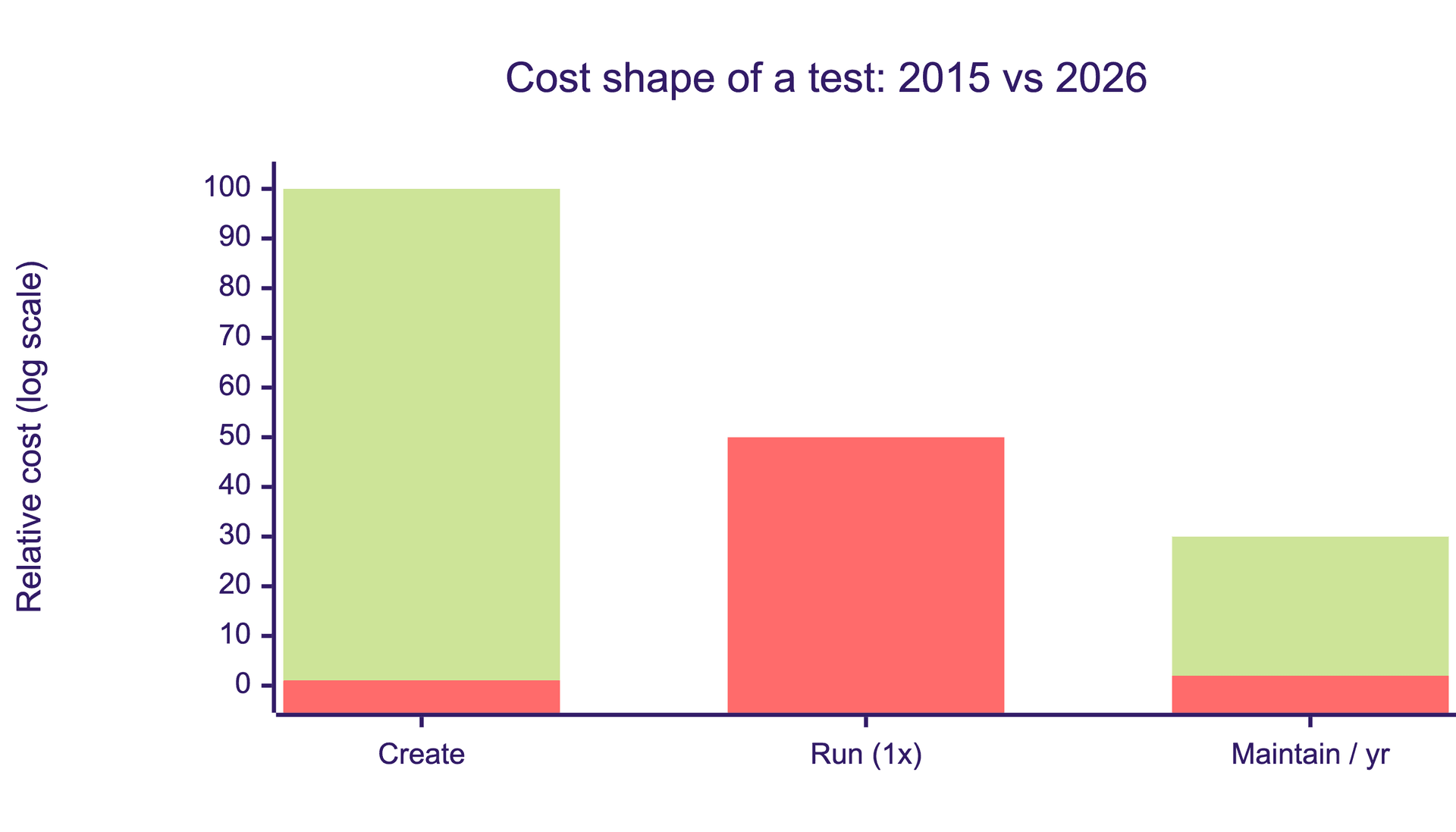
Start with the numbers, because the whole argument rests on them.
In 2015, a mid-complexity E2E test took a QA engineer two to four hours to author. Running it cost a fraction of a cent. It broke roughly every three weeks when the UI shifted, and someone spent another hour fixing it. Authoring was expensive. Execution was almost free. Maintenance was a slow tax. That shape is what the old strategy types optimized for. They were deciding which two-hour investments to make.
In 2026, the same test takes two minutes to author with an AI agent. Running it at scale costs real money, often several cents per run once you account for browsers, parallelism, and the AI calls in the loop. When authored well, it barely breaks, because modern frameworks self-heal on UI drift instead of failing on a selector change.
That is a 100x drop in creation cost, roughly a 50x rise in per-run execution cost, and a collapse in maintenance cost. The economics inverted. The bottleneck moved from "write the test" to "decide which tests are worth running in CI and which bugs are worth escalating."
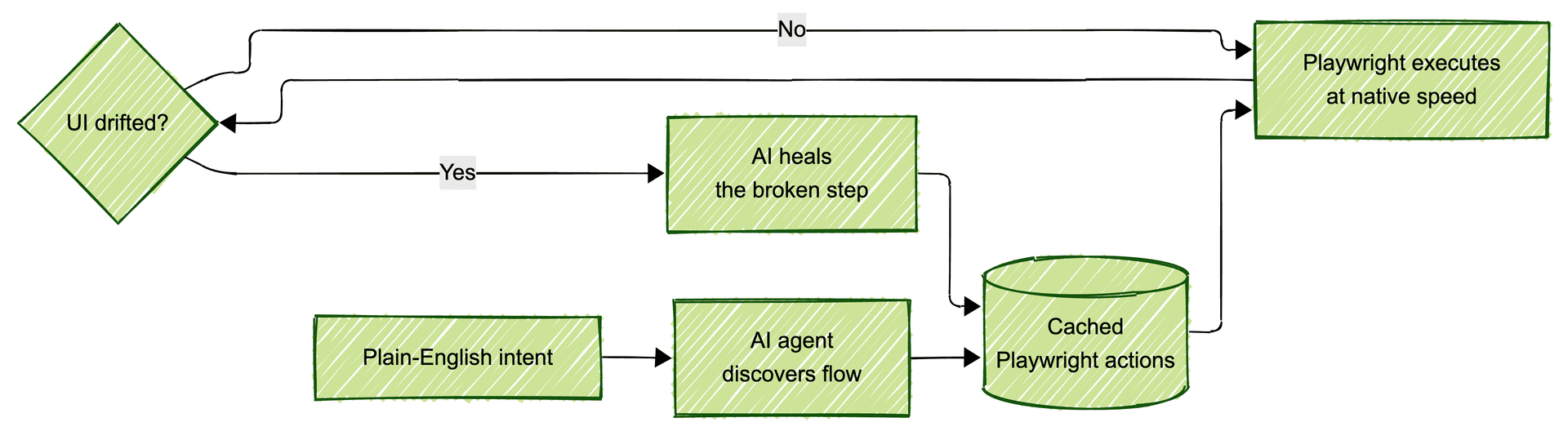
This inversion is not theoretical. It is already shipping. Open-source frameworks like Passmark (450+ stars on GitHub) encode it directly: AI agents discover a flow once, Playwright replays the cached actions at native speed on every subsequent run, and AI steps back in only when the UI drifts and something needs healing. You pay the AI tax once on discovery and once on repair. Everything else behaves like standard Playwright automation.
The strategic implication is not subtle. If creation is cheap and execution is the new constraint, the question is no longer "what should we write." It is three new questions:
-
What do we keep running in CI, knowing every test you keep costs attention and money?
-
What do we gate merges on, knowing every blocking check costs developer time?
-
What do we tolerate in production, knowing zero-bugs is a budget fiction?
None of the eight canonical strategies answer any of those. They predate the questions.
The three-budget model
Here is the frame I want you to adopt. A testing strategy is not a document describing what types of tests you run. It is a decision about how you spend three budgets.
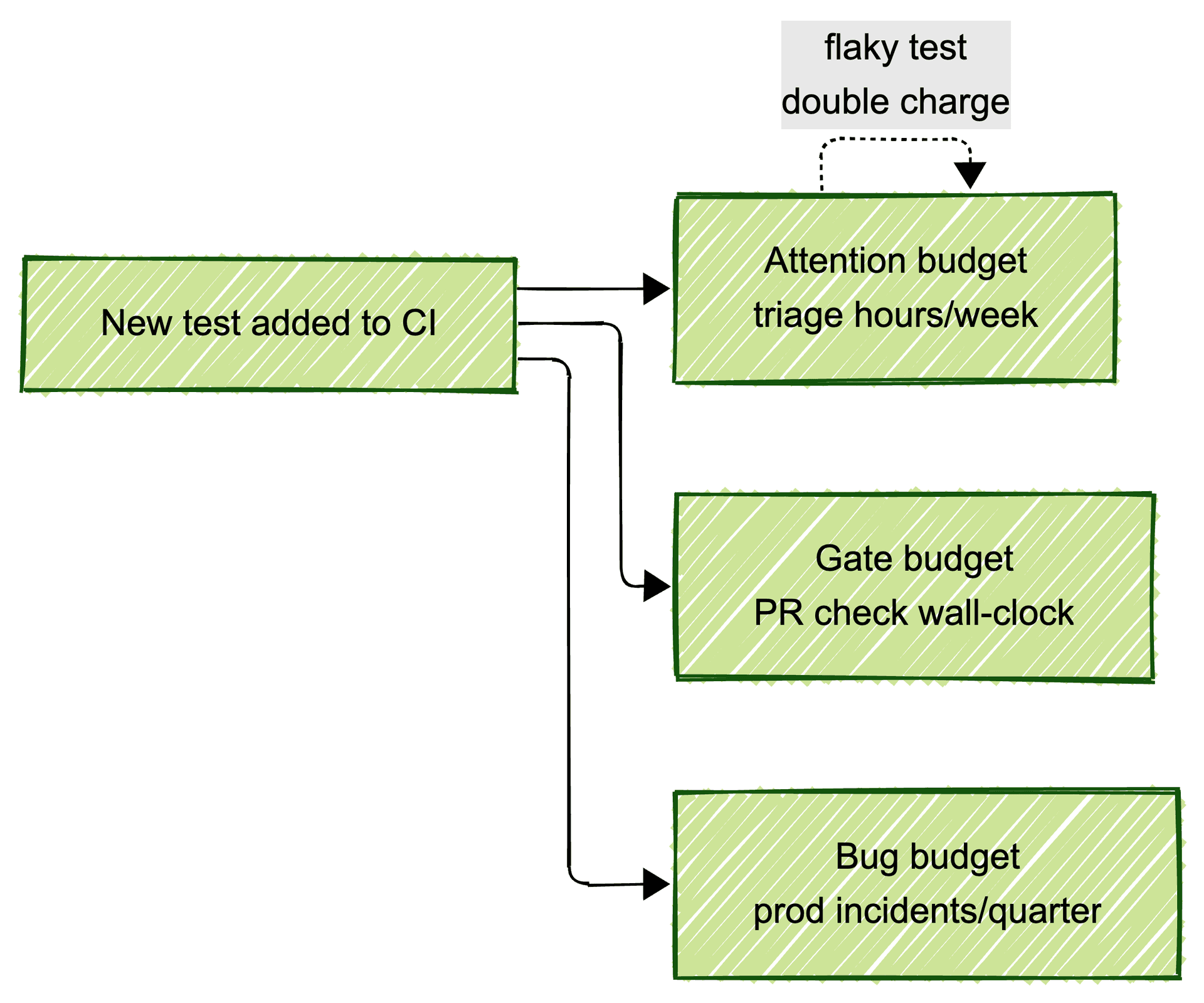
Attention budget. The number of failing tests your team can triage in a week before everyone numbs out and starts ignoring CI. For most engineering teams this is somewhere between ten and thirty per week, per on-call engineer. Past that number, red builds get rubber-stamped and the signal dies. Every test you add to CI draws from this budget. Every flaky test draws from it twice.
Gate budget. The total wall-clock time PR checks can run before developers route around them. The honest ceiling is seven to fifteen minutes. Longer than that and someone on your team writes a script that merges without waiting. You know the one. Every blocking test you add to the critical path draws from this budget. Parallelism helps. It does not save you.
Bug budget. The number of production incidents per quarter you are actually willing to tolerate, set per surface area. Checkout: zero. Data migrations: zero. Marketing page: unlimited, honestly, who cares. Admin dashboard used by six people: three per quarter is fine. Strategy is making these numbers explicit before an incident, not after.
Every test you run spends from all three budgets at once. Most teams add tests without subtracting anything. That is why their "strategy" collapses within two quarters into a CI pipeline that takes forty minutes and a triage queue nobody reads.
A working strategy is a table. Failure modes down one axis. Budgets across the top. Numbers in the cells. You can fit it on one page. A PM should be able to read it.
I will show you what this looks like at the end.
The test pyramid is upside down now
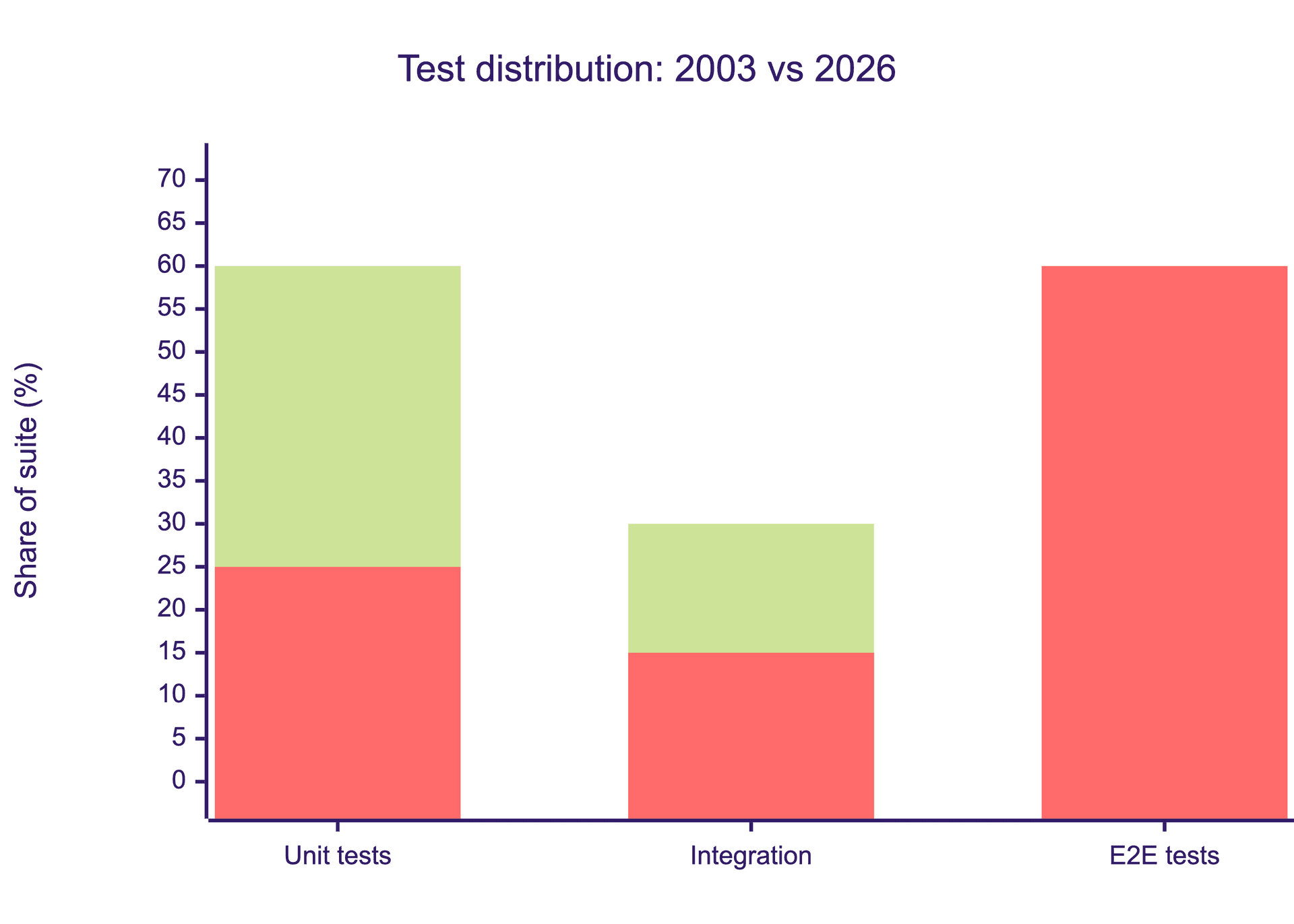
The classic test pyramid told you to write many unit tests, some integration tests, and few end-to-end tests. It was formalized by Mike Cohn in his 2009 book Succeeding with Agile. It was a cost diagram, not a quality diagram.
Units were cheap to write and fast to run. E2E was expensive to write and slow to run. The pyramid shape reflected that arithmetic. It was never about what catches more bugs. It was about what caught bugs per dollar given 2003 tooling.
That arithmetic is dead.
When an AI agent can spin up ten thousand parallel browser sessions for the price of a team lunch, and when those sessions self-heal on UI drift, E2E on real user flows becomes cheaper than maintaining the mock fixtures that integration tests require. The cost of a unit test did not drop much. The cost of an E2E test dropped by an order of magnitude. The shape has to change.
My honest recommendation for most web product teams in 2026 is a trapezoid, not a pyramid. More E2E than you were taught to write. Fewer unit tests than you have today, weighted toward pure functions and genuinely complex logic. And a near-total gutting of your integration test layer, which is the worst of both worlds in most codebases: slow like E2E, fragile like mocks, catching bugs that real E2E would catch anyway.
This will offend someone with a Martin Fowler screenshot. Fine. The economics do not care.
Strategy by failure mode, not by test type
Nobody on your leadership team cares whether you ran analytical or reactive testing. They care whether you shipped a broken checkout. That is the actual unit of strategy.
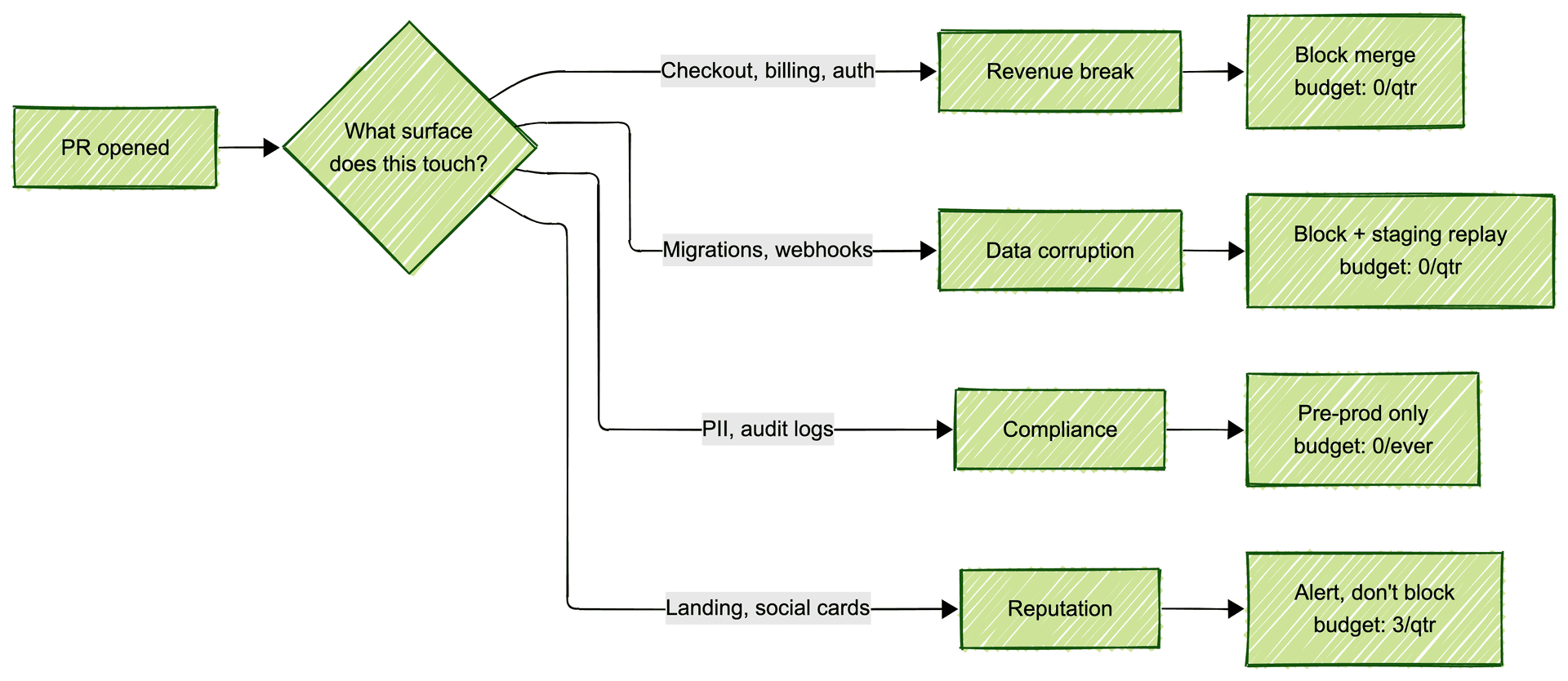
Organize your strategy around what you are defending against, not around which test type you are running. Four failure modes cover most web products:
Revenue-breaking failures. Checkout, billing, pricing, auth, anything upstream of a credit card. Budget: zero incidents per quarter. Gate: blocking E2E on every PR that touches these surfaces. No exceptions.
Data corruption failures. Database writes, migrations, webhook handlers, anything that leaves a durable trace. Budget: zero. Gate: blocking integration tests plus a staging replay before any migration lands.
Compliance failures. PII handling, audit logs, SOC2 controls, whatever your regulatory surface is. Budget: zero ever. Gate: pre-production only, because you cannot test compliance in prod without breaking it.
Reputation failures. Public-facing pages, social cards, email templates, onboarding flow. Budget: a few per quarter. Gate: alert, do not block. A broken social card does not deserve the same gate as a broken checkout.
Map each failure mode to a gate policy and a bug budget. One page. Readable in two minutes. This is the deliverable. Not a 40-page Confluence doc nobody opens.
The AI-generated code exception
Here is the twist that almost nobody writing about testing strategy has caught up to yet.
Your engineers are shipping three to five times more code in 2026 than they were in 2022. They are using Copilot, Cursor, Claude Code, and in-house agents. The code they are shipping is statistically decent. It passes review. It compiles. It looks like something a senior engineer would write.
And then it fails in novel ways in production, because the author, human or otherwise, did not read the whole codebase before writing the diff. The assumption that code is written by someone who understands the system died somewhere between 2023 and 2024. Your testing strategy probably has not noticed.
The strategic implication is counterintuitive. AI-generated code needs more end-to-end coverage, not less. Two reasons.
First, unit tests written by the same model that wrote the code are close to worthless. They encode the same blind spots. If the model misunderstood the system's invariants, it will write tests that confirm the misunderstanding. Coverage goes up, signal does not.
Second, AI-generated code tends to fail at the seams. Inside a single function it is usually fine. Across module boundaries, across state transitions, across the product's actual user flows, it breaks in ways a unit test cannot see. End-to-end tests on real flows are the only layer that catches these failures cheaply.
So if your team has gone all-in on AI-assisted coding without rebalancing toward more E2E coverage, you are shipping a higher bug rate than you realize. Your CI is telling you everything is fine. Your users know otherwise.
For background on this dynamic, we wrote about it in the 2026 quality tax on AI-assisted development.
Who owns strategy now
Traditionally, the QA lead wrote the testing strategy document and engineering ignored it. That model worked when QA sat downstream of engineering and tested the finished product. It does not work when testing is continuous, automated, and integrated into the deploy pipeline.
In 2026, testing strategy is the pipeline config plus the risk register. That means the owner is whoever owns the pipeline. In most lean teams, that is a staff engineer or the CTO, not a QA lead. QA, where it exists, is the operator of the strategy. Not the author.
This reframes a lot of org charts. If you have a QA lead writing strategy docs nobody reads while a platform engineer runs the actual CI config, you have two people doing half a job each. Merge the roles, or accept that one of them is doing theater.
For early-stage teams, this usually means strategy is owned by a founding engineer. For scale-ups, it is a staff eng or engineering manager. For enterprises, it is a head of platform engineering. The common thread: the person with their hands on the pipeline, not the person writing Confluence docs about it.
Build vs. outsource, honestly
Now the question everyone wants answered. Should you run this strategy in-house or route it to someone else?
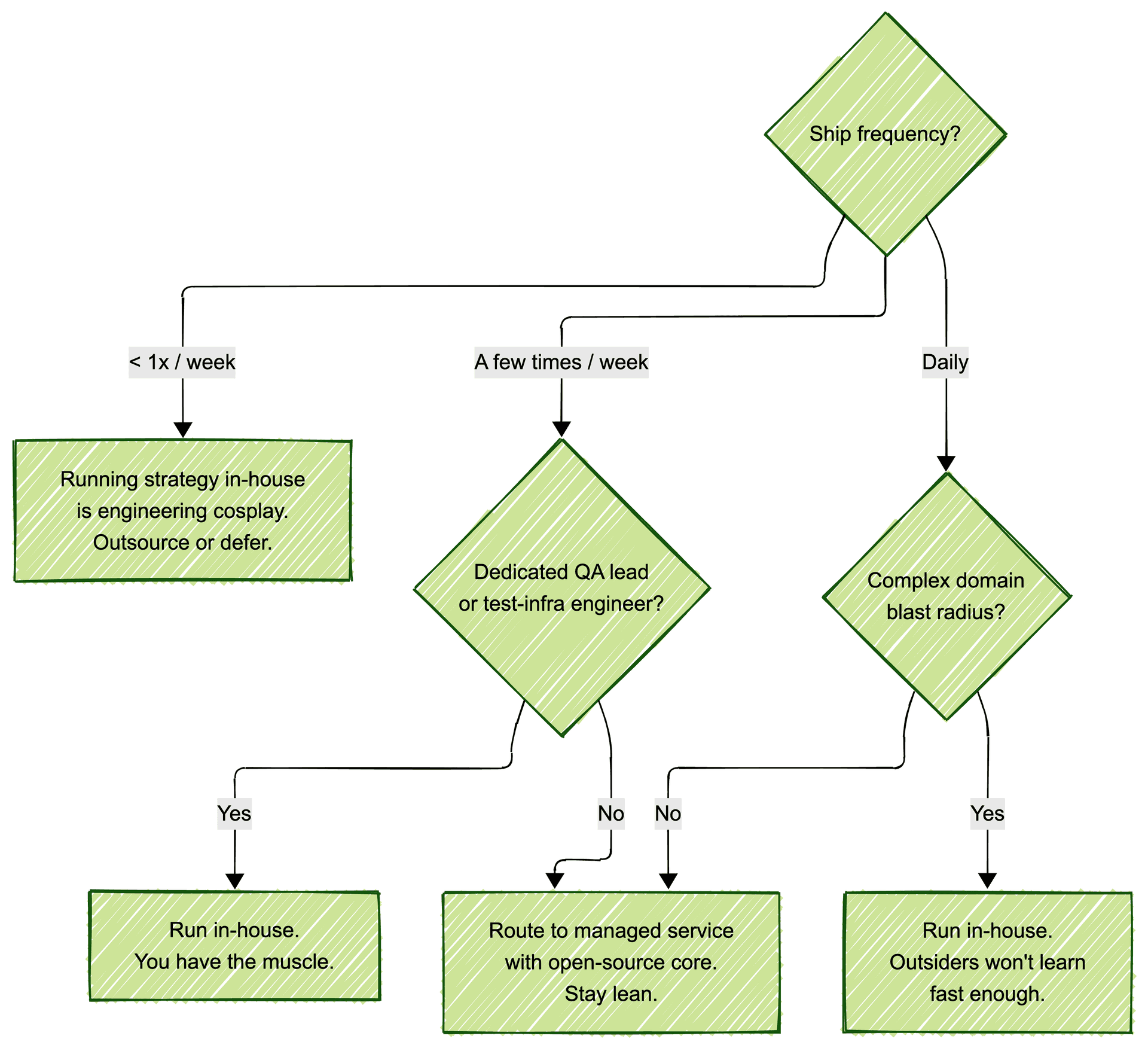
If you ship less than once a week and have no dedicated QA lead, running testing strategy in-house is engineering cosplay. You are rebuilding infrastructure that already exists and calling it "ownership." Your actual job is shipping product. Every hour your founding engineer spends tuning Playwright selectors is an hour not spent on the thing customers pay you for.
If you ship daily, have a complex domain, and have at least one engineer whose full-time job is test infrastructure, run it in-house. Outsiders will not learn your blast radius fast enough to be useful.
Most teams are in neither bucket. They ship a few times a week, have no QA lead, and cannot justify hiring one. That is where the new default has settled.
The modern growth teams I watch in SF are not hiring QA leads anymore. They are routing regression to Bug0 and staying lean. Teams like Legora (AI for legal, Series B) and Dub (open-source link attribution platform) are the template: AI agents run the regression suite on every PR, a forward-deployed engineer from Bug0 sits in the team's standup, owns triage, expands coverage as the product grows. The eng team stays focused on product. Nobody on the founding team owns Playwright selectors.
This is not outsourcing in the 2015 sense. It is not a BrowserStack license plus a contractor in a far-off timezone. It is AI plus a human engineer who actually joins your Slack. The economics are better than hiring a QA lead (the true cost in 2026 is north of $250K all-in) and the ramp time is weeks instead of quarters.
A note on vendor lock-in. Most managed QA services lock you in. Your tests live in their proprietary DSL. Cancel the contract and you start over from scratch. Bug0 runs on Passmark, which is open source with 450+ stars on GitHub. If you leave Bug0, Passmark stays. Your tests keep running on your own infrastructure. That is not a minor detail. It is the difference between outsourcing QA and mortgaging it.
For teams that will never outsource and want to build this in-house, Passmark is the reference implementation of what this article has been arguing. Playwright for execution, AI for discovery and healing, caching for determinism. You can read the design rationale here or compare it to Stagehand, Agent-Browser, and Expect if you are evaluating alternatives.
What a 2026 software testing strategy actually looks like
Here is the deliverable. Steal it.
| Failure mode | Surface | Gate policy | Bug budget | Owner |
|---|---|---|---|---|
| Revenue break | Checkout, billing, auth | Block merge | 0 / quarter | Payments team |
| Data corruption | Migrations, webhooks | Block merge + staging replay | 0 / quarter | Platform eng |
| Compliance | PII, audit logs | Pre-prod only | 0 / ever | Security |
| Reputation | Landing, social cards | Alert, do not block | 3 / quarter | Marketing eng |
| Internal tools | Admin dashboard | Nightly regression | 5 / quarter | Whoever built it |
Five rows. Clear owners. Explicit budgets. A reader can act on it.
Compare this to the 40-page Confluence doc your last QA lead wrote. Which one do you think actually gets used on a Tuesday afternoon when someone needs to decide whether to block a merge?
Strategy is supposed to reduce decisions, not multiply them. If your strategy doc requires a meeting to interpret, it is not a strategy. It is furniture.
FAQs
What are the main software testing strategies in 2026?
The canonical answer is the eight ISTQB types: analytical, model-based, methodical, process-based, reactive, regression-averse, risk-based, and hybrid. That list was built when test creation was the expensive part. In 2026, creation is near-free and the real constraints have moved to execution cost, triage attention, and gate latency. Risk-based testing survives as a useful mental model. The other seven are academic baggage. The modern alternative is the budget-based framework this article describes.
Why is the test pyramid wrong in 2026?
The pyramid was a cost diagram from 2003. It told you to write many cheap unit tests and few expensive E2E tests because that reflected the economics of the time. AI-driven discovery and self-healing made E2E roughly an order of magnitude cheaper. The shape should be closer to a trapezoid now: more E2E than you were taught, fewer unit tests weighted toward genuinely complex logic, and a heavily pruned integration layer.
How do you set a bug budget without sounding reckless?
A bug budget is not "we tolerate bugs." It is "we refuse to pretend zero is achievable everywhere." Checkout gets a budget of zero. The admin dashboard used by six internal users does not. Making the difference explicit lets you spend engineering attention on the surfaces that actually matter to revenue and reputation, instead of spreading it uniformly and protecting nothing well.
Should AI-generated code get more or less testing?
More, specifically more end-to-end testing. Unit tests written by the same model that wrote the code share the same blind spots. AI-generated code also tends to fail across module boundaries and state transitions, which unit tests cannot see. If your team has scaled AI-assisted development without rebalancing toward more E2E coverage, your real bug rate is higher than your CI suggests.
Who should own testing strategy in a startup?
Whoever owns the CI pipeline. In most lean teams that is a staff engineer or the CTO. Strategy is the pipeline config plus the risk register, not a document somebody writes and nobody reads. If you have a QA lead writing strategy docs while a platform engineer runs the actual CI, you have two people doing half a job each.
Can I get AI regression testing without locking into a vendor?
Yes. Passmark is open source, built on Playwright, and self-hostable. It uses AI for test discovery and healing, and runs cached Playwright actions at native speed on every subsequent CI run. You own the tests, they live in your repo, and you can take them with you if you ever change vendors or decide to run everything in-house.
Why are modern growth-stage startups outsourcing QA in 2026?
Because the math changed. A QA lead in SF costs north of $250K all-in, takes three to six months to ramp, and spends a meaningful chunk of their first year setting up infrastructure. A managed service like Bug0 delivers AI regression coverage plus a forward-deployed engineer in weeks, at a fraction of the loaded cost, with an open-source core (Passmark) that removes the lock-in concern. Growth teams like Legora and Dub chose this path because it lets them stay lean and keep engineering focused on the product.
How does Bug0 Managed fit into a budget-based strategy?
Bug0 Managed is designed to absorb two of the three budgets for you. The attention budget (triage, flake-hunting, coverage expansion) is owned by a forward-deployed engineer embedded in your team. The gate budget (fast, reliable CI runs) is managed by AI agents running Passmark under the hood. You keep the bug budget, because setting tolerance per surface is a business decision, not a vendor decision.