

tldr: The eight canonical types of software bugs every QA textbook lists (functional, logical, syntax, runtime, performance, security, compatibility, UI) are still right in 2026. What's different is what fills each bucket. AI hallucination is the new top source of logical bugs. Prompt injection is dominating security. Shadow DOM is breaking compatibility tests. LLM tokens are the new performance metric. Here's what changed inside each category, and where most teams are still under-covering.
Most "types of software bugs" articles online list the same eight categories and call it done. They give you the textbook definition, three examples, and a generic recommendation to "use modern test automation." The list isn't wrong. The list is incomplete in 2026.
Across the engineering teams I've worked with over the last few years, the pattern across every team is consistent: they know the eight types of bugs, but their coverage is shaped for a stack that doesn't exist anymore.
AI assistants write the code. LLM features sit in the request path. Frontends ship Web Components by default. Bugs are still landing in the same eight categories. They just look completely different.
This is what I find frustrating about most articles on this topic. They paste in the 2010s definitions and never address what changed. AI didn't break the taxonomy. AI changed what fills each bucket, and most coverage is still built for the previous decade's stack. Here's what each one looks like now.
Each of the 8 bug types, with the 2026 shift inline
These are the eight categories every QA team should be able to name and define, with the 2026 reality of each one. I've ordered them by frequency at the teams I work with, not by textbook order.
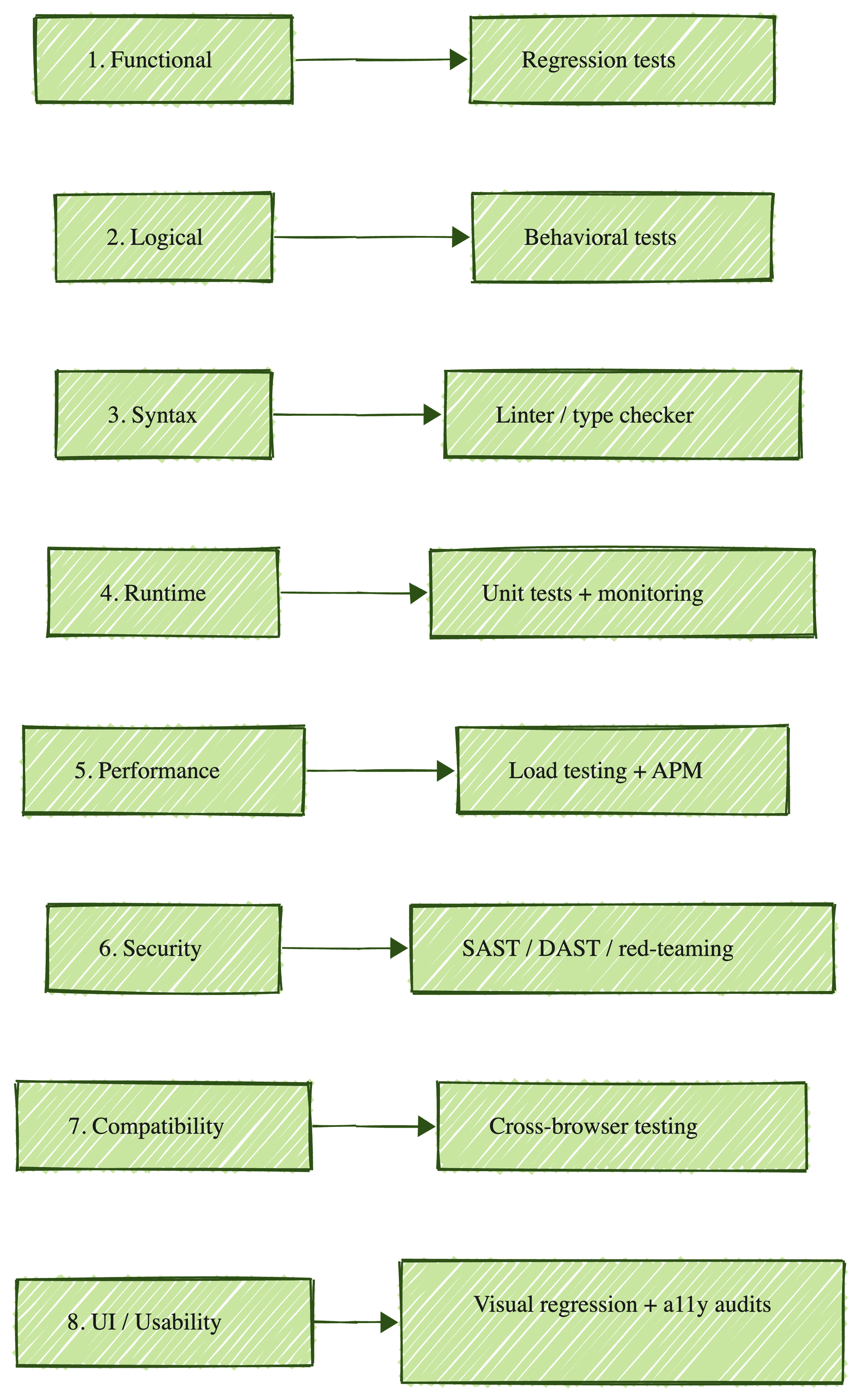
1. Functional bugs
Functional bugs ship more often than any other category in 2026, and the reason is deploy frequency. High-velocity AI-driven teams now push to production multiple times a day. Functional regressions ship faster than test coverage keeps up.
A functional bug is a defect where a feature behaves differently from what its specification requires. The code runs, but the output is wrong:
-
Login accepts wrong credentials
-
A discount code applies twice
-
Search returns the wrong result set
-
A webhook fires twice for the same event
None of this is new. What's new is the cadence at which these bugs ship past coverage. The failure mode is often the same: critical-flow regression coverage is years behind deploy frequency, and the team is patching the gap with retries and prayer.
The fix is a regression suite that self-heals when the UI changes. Tools that need babysitting just convert bug debt into maintenance debt.
The model winning here is AI-native regression coverage plus a Forward Deployed Engineer who owns triage and verification. Teams like Legora (AI for legal, Series B) and Dub (open-source link attribution platform) route their regression to Bug0 for exactly this reason.
2. Logical bugs
The fastest-growing source of logical bugs in 2026 is the AI assistant on the developer's screen. Cursor, GitHub Copilot, and Claude Code now write a meaningful share of production code. The model predicts the most likely-looking code, not the correct one.
It references functions that don't exist. Invents method signatures. Imports library versions that were deprecated two majors ago. The code parses, the linter is clean, and sometimes it even compiles. It throws at runtime because the function it called was never real.
A logical bug is a defect in the algorithm or business logic. The code runs, but the reasoning is wrong:
-
A discount calculator that multiplies instead of divides
-
An off-by-one error in pagination
-
Timezone math that ships invoices a day late
-
A retry loop that increments a counter past its limit
The defect class is logical even when the author is an AI. The catching strategy isn't the same.
The Stack Overflow 2025 Developer Survey reports that 45% of developers cite "debugging AI-generated code is more time-consuming" as a top frustration. 66% spend more time fixing "almost-right" AI-generated code. The bugs are harder to diagnose because the developer assumes the AI wrote correct code and skips the review step.
I've seen this play out in customer codebases. A developer asks Copilot for a helper function. Copilot writes it confidently. The unit test (also AI-generated) passes against the AI's hallucinated assumption. The real failure surfaces in production when actual user data hits the path.
Behavioural end-to-end tests are the only reliable defence, and they have to be written by someone other than the AI. AI-generated unit tests share the false assumptions that produced the bug. Treat AI-generated test coverage as suspect when it passes against AI-generated code.
3. Syntax bugs
Most QA planning still treats syntax bugs as a category that needs dedicated coverage. It doesn't.
Compilers and linters catch nearly all syntax bugs before commit. ESLint, Ruff, gofmt, rustfmt. AI assistants almost never introduce syntax bugs because the models are trained on syntactically valid code; the bugs AI introduces are semantic, not syntactic. In ten years of writing and shipping code, the only syntax bugs I've seen reach production were in one-off scripts and Lambda handlers nobody bothered to lint.
If your editor doesn't catch the bug, your pull request gate should. Save the QA budget for problems that actually escape, and move on.
4. Runtime bugs
A runtime bug surfaces only when the code is executing. The program compiled cleanly, but throws an exception under specific data:
-
Null pointer exceptions
-
Division by zero
-
Stack overflows
-
Unhandled promise rejections
-
Race conditions in async code
In 2026, a growing share of runtime exceptions is the runtime expression of AI-hallucinated logical bugs. The diagnosis is "uncaught exception"; the root cause is "the AI invented this function."
The other 2026 reality, and the one I think most teams misclassify the most: flaky tests usually aren't flaky. Across the 200+ teams we've worked with, 60% to 70% of failures the team had labelled "flaky" turned out to be real production bugs that retry logic was masking.
The test framework wasn't unreliable. The system under test was.
The reason teams get this wrong is that "flaky" is a comfortable label. Calling a test flaky lets you move on. Calling it a real bug means investigating the system under test, filing a ticket, and arguing with the developer about reproduction steps. Most teams pick the comfortable label and ship the bug.
Catch the underlying logical bug with behavioural testing. Catch runtime exceptions with any production observability. Don't retry past failures. Investigate them.
5. Performance bugs
Performance bugs in 2026 aren't just latency and memory. An LLM-integrated feature can be functionally correct, fast on response time, and quietly cost $400 a day extra because someone re-instantiated the embedding model inside a loop. Tokens-per-request is the new performance metric. Most teams have no test coverage for it.
The category itself hasn't moved. A performance bug is code that returns the correct result but consumes too many resources doing so. Slow queries, N+1 patterns, memory leaks. What's new is the resource type:
-
Old performance: milliseconds and megabytes
-
New performance: tokens and dollars
Load test with k6. APM with Datadog. For LLM features, instrument tokens-per-flow as part of the test contract, and fail the build on cost thresholds the same way you'd fail it on a slow page.
I've watched a Series B startup discover an embedding-loop bug only after their OpenAI bill ran 8x over forecast for three weeks. Nobody had thought to write a test for "this feature should cost less than X cents per call." That test would have caught it on day one.
6. Security bugs
Every QA blog in 2026 treats prompt injection like a new species of bug. It isn't.
Prompt injection is the same defect class as SQL injection and XSS. Untrusted user input reaches a privileged execution context without validation. The execution context happens to be a language model instead of a SQL parser, but the shape of the bug is identical:
-
SQL injection: untrusted input plus SQL parser. Fix: parameterise the query.
-
XSS: untrusted input plus HTML parser. Fix: escape the output.
-
Prompt injection: untrusted input plus LLM. Fix: not here yet.
The reason teams keep getting hit by it is that the validation problem is harder this time. With SQL, you could parameterise queries. With LLMs, there's no architectural separation between system instructions and user content. Both arrive as text in the same context window, and any input the user controls can override system behaviour.
OWASP put prompt injection at the top of its LLM Top 10 in 2023, and the 2025 edition kept it there.
Simon Willison, who coined the term in 2022 and has been the loudest voice on the problem since, has reframed the risk in 2025 as the "Lethal Trifecta." An LLM is dangerous when it has all three of these at once: access to private data, exposure to untrusted content, and the ability to communicate externally. Most AI agent products in 2026 have all three by default. That's the actual attack surface, not the chat box.
The threat isn't new. The fix isn't here yet.
Catch it the same way you catch other injection flaws. SAST and DAST for the broader security surface. For LLM features, specialised red-teaming tools like Garak or Promptfoo that exercise known injection vectors.
Treat anything routing user input through an LLM as a security surface that needs adversarial testing, not a feature that needs a unit test.
7. Compatibility bugs
The most common compatibility break I've seen in 2026 isn't browser-vs-browser anymore. It's test-environment-vs-production. Lit, Stencil, and native Custom Elements are mainstream now, and most modern design systems ship components with shadow roots.
The bug looks like this:
-
A team's
<Button>component migrates to a native Web Component with a shadow root. -
The existing Cypress selector
cy.get('[data-testid="submit"]')no longer finds the element. The button lives inside a shadow root, and older Cypress patterns don't pierce the shadow DOM. -
The button renders. The user clicks it. The test reports "element not found."
-
Nothing about the production behaviour changed. Everything about the test reality did.
A compatibility bug is still what the textbook says: code that behaves differently in different environments. What shifted is which environments matter. Cross-browser (Chrome vs Safari, iOS 17 vs 18) is still real and still needs cross-browser testing. The new surface is inside your own test code.
Playwright pierces the shadow DOM by default with most locators. If you wrote your suite before 2024, audit it. The migration cost is real, but the alternative is a test suite that goes silent on every design system rev.
8. UI and usability bugs
UI bugs used to be the lowest-stakes category. Cosmetic. Annoying. Easy to backlog. The EU Accessibility Act changed that:
-
WCAG 2.2 compliance is now a legal floor for B2B SaaS selling to European customers
-
An accessibility regression in production is no longer a P3 in your tracker, it's potential lawsuit material
-
EU Accessibility Act enforcement has been active since mid-2025
The mechanism is quiet. A designer swaps a <div onclick> for a <button> to fix one issue. The fix changes the accessibility tree. Screen-reader tests that depended on the old structure break. Visual diff is clean. Functional test passes. Your a11y suite, if you have one, turns a warning into a P1.
The bigger problem is that most teams don't have an a11y suite. Visual regression handles layout drift, but accessibility regressions live in the ARIA tree, which most CI runs don't assert against. Wire axe-core into CI, fail the build on tree-level regressions, and stop shipping liability.
Severity and priority: the other half of bug classification
Knowing the eight types of software bugs is the start. Severity and priority are how teams actually route bugs through the work queue, and most bug-tracker workflows in 2026 ask for all three at file time.
Severity is impact:
-
Critical: data loss, security breach, payment failure, total outage
-
High: core feature broken for a meaningful slice of users
-
Medium: quality-of-life degradation; workaround exists
-
Low: cosmetic

Priority is urgency:
-
P0: Drop everything. Hotfix today.
-
P1: Fix this sprint.
-
P2: Fix next sprint.
-
P3: Backlog.

A typo in the marketing site is low severity. If it spells the CEO's name wrong on launch day, it's also P0. The two dimensions are independent for a reason. Conflating them is the most common mistake I see in junior QA workflows. Junior engineers default to severity-equals-priority. Senior engineers end up re-triaging the entire backlog every quarter.
FAQs
How many types of software bugs are there?
The canonical taxonomy is eight: functional, logical, syntax, runtime, performance, security, compatibility, UI/usability. Some lists expand to 12 or 16 by splitting categories. The eight in this piece are the set every QA team should be able to name and define on day one.
What's the most common type of software bug in 2026?
Functional bugs, by volume. Regression bugs (a sub-pattern of functional) are the most common cause of customer-reported issues at high-velocity teams. AI-generated hallucination is the fastest-growing source of logical bugs.
What's the difference between a bug, a defect, and an error?
In strict ISTQB terminology, an error is the human mistake a developer makes, a defect is the resulting flaw in the code, and a bug is the visible manifestation when the defect is triggered. In practice, most teams use the three terms interchangeably, and that's fine.
Where do AI hallucination bugs fit in this taxonomy?
Logical bugs, with a runtime expression. A hallucinated function call is a logical defect at authorship time and a runtime failure at execution time. The defect is logical, even though the author was an AI.
Where does prompt injection fit?
Security bugs. OWASP classifies it the same way, as LLM01 in the Top 10 for LLM Applications. The attack vector is new. The defect class is the same as other input-validation flaws.
Where do Shadow DOM and Web Components selector bugs fit?
Compatibility bugs. The test environment's DOM model doesn't match the production DOM model. Same shape of bug as cross-browser rendering differences, a new cause.
Where do flaky tests fit?
Flaky tests aren't a bug type. They're a symptom of a race condition (runtime), an environmental difference (compatibility), or a timing-dependent assertion (logical). In the 200+ customer onboardings we've seen, 60% to 70% of failures labelled flaky turn out to be real production bugs that retries were hiding.
Do AI coding assistants make QA easier or harder?
Easier on the writing side, harder on the failure side. AI lets you ship more code per developer per week, but the code that ships needs more behavioural testing, not less. Most QA tooling and test methodology were built around a human author and a human reviewer. Both assumptions need to be revisited in 2026, especially for any team where an AI is drafting more than half the production code.
When does a managed QA service make sense over in-house QA?
If you're shipping weekly and don't have a QA hire, the math has tipped. A fully-loaded QA engineer costs $130–150K/year. Tool licenses add $5–15K. Maintenance and flake debugging eats 30–50% of dev time on top of that.
A managed service like Bug0 delivers AI regression coverage plus a Forward Deployed Engineer who maps your critical flows, files real bugs with repro steps, and gates every release. 100% coverage in 4 weeks, 0% flake, billed flat at $2,500/month. The trade-off versus self-serve tools is who owns the maintenance burden.
The eight categories aren't broken. Coverage built for the 2018 stack just stopped working in 2026, and most teams are still patching the gap with retries and tool sprawl.
The fastest fix I've watched work is owning the gap end-to-end: knowing exactly which 2026 mutation each category is bleeding through, and building (or buying) coverage that addresses the actual failure mode instead of the textbook one.



