

tldr: White box testing means designing tests by reading the source: which branches execute, which paths get covered, which conditions get evaluated. Five structural coverage techniques (statement, branch, condition, path, MC/DC) plus mutation testing as a test-quality check make up the working set. Most application teams ran statement coverage and skipped the rest because the cases were too expensive to hand-write. AI agents collapsed that cost. This post covers what each technique catches, what it now costs to run, and why white box testing only earns its keep when it runs alongside black box regression on the same release.
I spent the first stretch of my career writing application code at Capgemini. We had test suites. SonarQube was wired into the build. We reported statement coverage percentages in sprint reviews. I shipped bugs constantly that my own unit tests had passed on, because the tests covered the paths I had thought of and missed the paths I had not.
Nobody on the team called this a white box testing problem. We thought in terms of "wrote tests, tests passed, shipped." That is white box testing as most teams actually practise it. The discipline exists. The tooling is there. The gaps are visible if anyone looks. Almost nobody looks.
The reason was never that white box testing is hard to understand. It is one of the older disciplines in software engineering. The reason was that running it properly required hand-writing test cases for every path the code could take. That labour was the binding constraint. AI agents have removed it.
The interesting question now is not what white box testing is. It is what it now costs to run, and what running it actually buys you when you do.
Let me walk you through it.
What white box testing actually is
White box testing evaluates software by reading the internal code, control flow, and data flow. Clear box, glass box, transparent box, structural testing. Same thing. The tester has access to the source and designs cases that exercise specific code paths.
You read the function. You list the branches, conditions, and loops. You write inputs that force each one to execute. If a branch was never executed, your test suite has a gap. No running application required. No user journey needed. Just source.
This is the opposite question from black box testing, which evaluates behaviour from outside the system with no view of implementation. Most production systems need both on the same release. The companion piece on black box testing covers the user-facing layer.
How it actually gets done in 2026
A working pass goes roughly like this. You read the function. You build a control flow graph, mentally or actually. You apply a coverage technique to derive cases, run them, and iterate on the gaps. Different sources cut this into three steps, five, seven. The shape matters less than what work sits where.
Two pieces stay human: figuring out what the function should do, and deciding which functions are worth this attention. Slack threads, design docs, risk judgment. All of that.
The rest is where AI agents now do most of the work. Reading the source, building the call tree, generating inputs for every branch, executing the suite, and surfacing the gaps. Coverage analysis was always technically available. Now it is CI-default for teams of five.
The techniques are unchanged. The labour shifted from typing to deciding.
Here is the part most teams are still mispricing. White box testing was rationed for fifty years because writing the cases was expensive. Teams ran statement coverage, skipped MC/DC, and treated mutation testing as a research curiosity. Now the expensive techniques are affordable. Teams that haven't updated their stack are leaving the cheapest defect detection on the table.
And honestly, most of them won't update until a customer-facing incident forces it. That is the part I find most frustrating. The tooling sits there. The reports get generated. Nobody reads them.
The five coverage techniques and one test-quality check
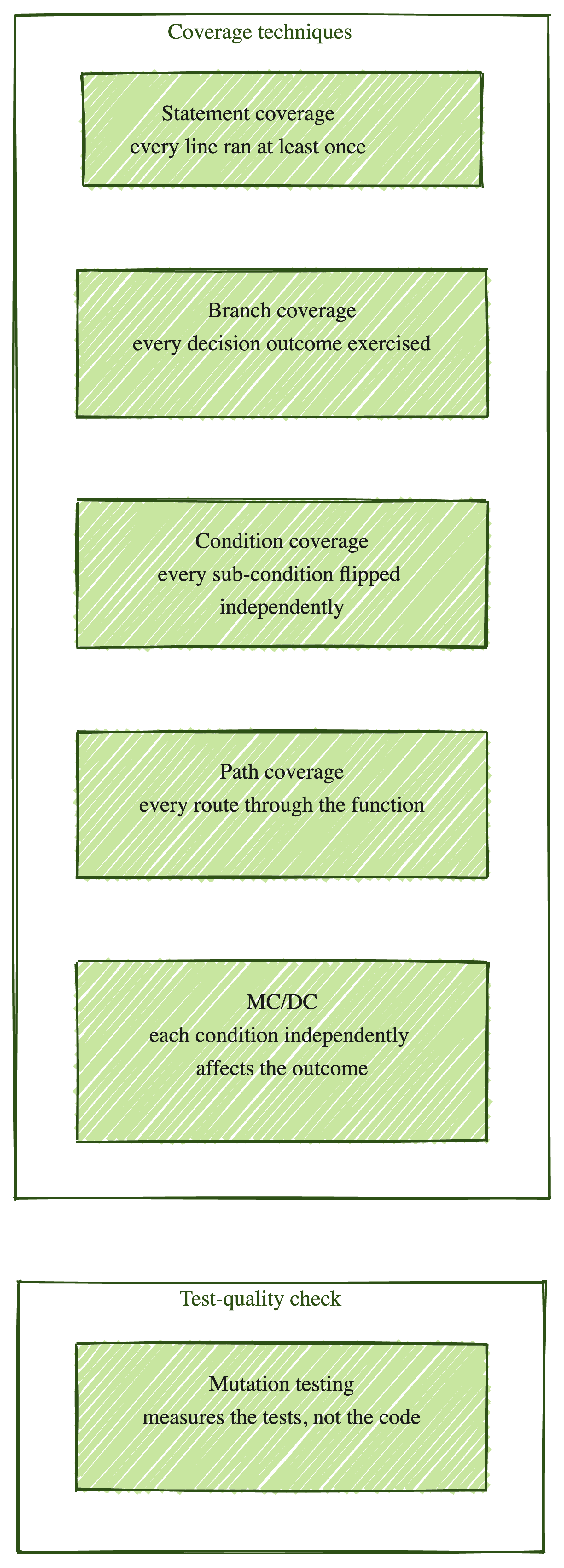
Worth being precise here. Statement, branch, condition, path, and MC/DC are coverage techniques. They measure how much of the code your tests exercised. Mutation testing is different. It measures how good those tests are. Lumping all six under "coverage" is common, but they are not the same kind of measurement.
Statement coverage
Hit every statement at least once. The technique most teams ran and the only one most ever measured.
function applyDiscount(total) {
if (total >= 100) return total * 0.8;
if (total >= 50) return total * 0.9;
return total;
}
Three inputs (120, 75, 30) hit all three statements. Statement coverage: 100%. The function still ships free orders when an upstream override flag is wrong. Hitting a statement does not prove the logic inside it is right.
The technique is fine. The expectation that 80% statement coverage means anything in 2026 is the problem. A function with 50 statements where your tests execute 40 gives you 80%. The 10 you missed could be the only ones with bugs.
The only reason to stop at statement coverage today is inertia. I have stopped accepting it as an excuse on any project I touch.
Branch coverage
Every decision point has at least two outcomes. Exercise all of them.
function canLogin(passwordOk, failedAttempts) {
if (!passwordOk) return false;
if (failedAttempts >= 3) return false;
return true;
}
Two decisions, four branches. Branch coverage needs four cases. Statement coverage gets away with two. This is the one I wish I had run as a developer. Most of the bugs I shipped were branch-coverage gaps wearing statement-coverage clothes.
Most coverage tools (Istanbul, JaCoCo, coverage.py) already report branch coverage alongside statement coverage. Reading the report and acting on it was the friction. Agents now write the missing test cases automatically from the gap list. What used to take an afternoon now takes seconds.
Condition coverage
One step finer than branch coverage. Inside a single decision, each sub-condition needs to take both values independently.
function shouldInvalidate(ttlExpired, tagMatch, explicitPurge) {
return ttlExpired || (tagMatch && explicitPurge);
}
Branch coverage is satisfied with two cases (the whole expression true or false). Condition coverage requires ttlExpired, tagMatch, and explicitPurge each to flip independently. That is where the cache bug that ships every quarter actually hides.
This matters when your logic combines flags whose interactions you have not thought through. I think condition coverage is where most production logic bugs actually live, more than statement or branch, because flag combinations are how features ship and how features break. AI generators handle the combinatorics natively.
Path coverage
Every possible route through the function. The combinatorial math is the catch.
function parseDate(input) {
if (isIso(input)) return fromIso(input);
if (isRfc(input)) return fromRfc(input);
if (isUnix(input)) return fromUnix(input);
if (isNaturalLang(input)) return fromNL(input);
return null;
}
Five paths. Easy. A function with twelve binary decisions has up to 4,096 paths, which is why path coverage was always defined and almost never measured.
I think path coverage is the most underrated technique in the working set. AI agents now enumerate the paths from the control flow graph and generate the inputs. For business logic where a missed path costs you a refund or a compliance ticket, this should be the new default.
Modified condition/decision coverage (MC/DC)
For every condition in a decision, show that condition independently affecting the outcome.
function canEdit(user, resource) {
return user.role === 'admin'
|| (user.role === 'editor' && resource.shared);
}
Three conditions. At least four test cases in the unique-cause form. Flip one condition, watch the result flip, hold the others fixed. Authorisation bugs live here.
MC/DC is the structural coverage standard mandated by DO-178C for Level A avionics software. It has been the gold standard for high-assurance code since DO-178B shipped in December 1992.
The argument for why it matters comes from a 2001 NASA technical report by Hayhurst, Veerhusen, Chilenski, and Rierson. Exhaustive multiple-condition coverage needs 2^n test cases. The report calls running 2^n tests for large n "impracticable" for avionics. MC/DC gets you there with n+1 tests instead.
That tractability argument is what kept MC/DC alive in aerospace while everywhere else skipped it. The cost reason no longer applies.
If you ship code where a bug means financial loss, customer harm, or regulatory exposure, MC/DC on the relevant paths is now affordable. I expect fintech and healthcare teams to adopt it on high-risk paths inside 12 to 18 months. Most of them do not know it is on the table.
Mutation testing
Not coverage. Quality of the test suite itself.
function compare(a, b) {
if (a < b) return -1;
if (a > b) return 1;
return 0;
}
Mutate it. Change < to <=. Change return -1 to return 1. Run the tests. If anything still passes, your tests do not actually verify the contract. The mutation score is the percentage of mutants your tests killed.
For most of its history, this was a research topic. The runtime was bad, the equivalent-mutant false-positive rate was high, and almost nobody had the budget. StrykerJS for JavaScript and TypeScript, PIT for Java, and Mutmut for Python now ship with sensible defaults and run in CI on reasonable timescales.
Mutation testing is the only way to find out whether your tests are actually doing anything. And it is now cheap enough to ask.
Where it sits in the stack
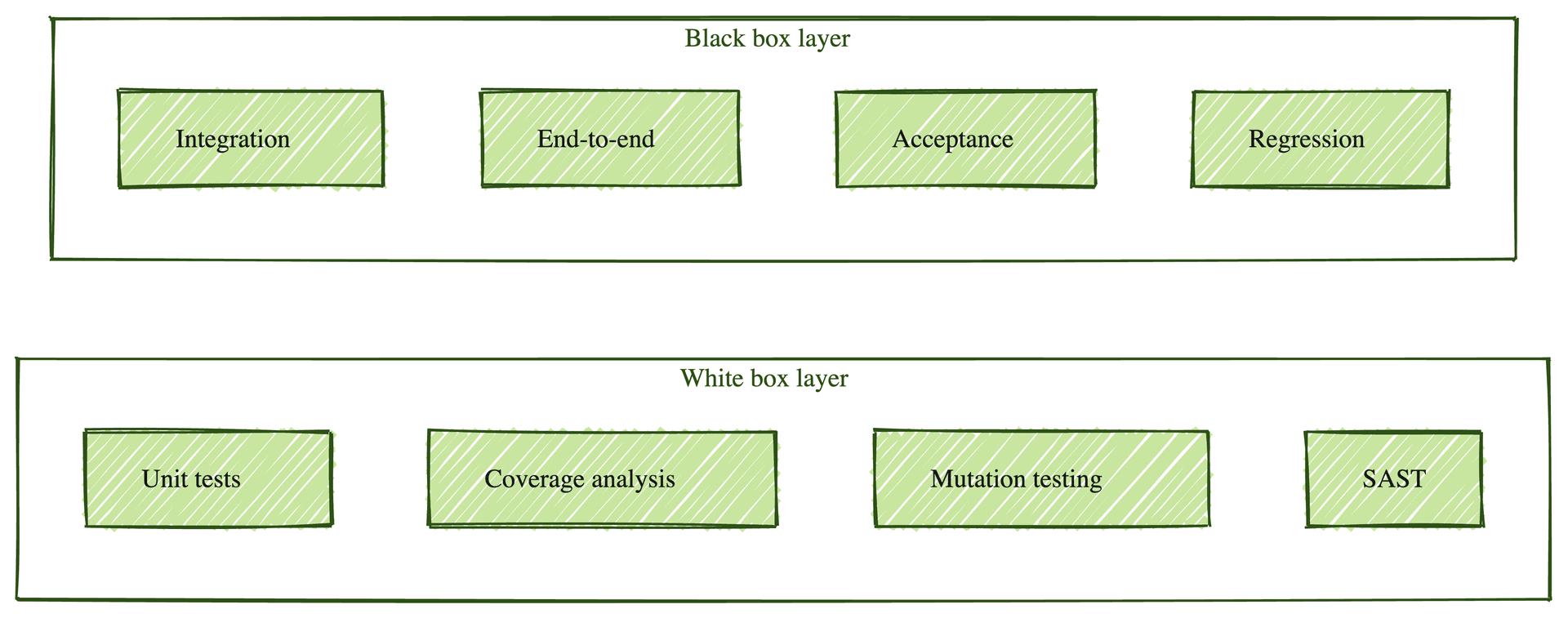
White box testing is most often categorised by the application layer it inspects.
At the unit level, you test a single function or class in isolation. Statement and branch coverage live here for most teams, and the AI-agent labour reduction is most dramatic here.
Integration is more interesting. Two or more units composed together, tested with knowledge of the contracts between them. Most teams ship integration tests as black box: drive the API, check the response. The white box version is rarer and catches different bugs.
A system-level white box is rare on purpose. By the time you are testing the whole system, what you can usefully measure is behaviour, and behaviour is black box territory. SAST tools are the exception, since they read the entire codebase without running the system.
The useful distinction is not white box at unit level versus white box at system level. It is white box anywhere in your stack versus black box anywhere in your stack. Different layers, asking different questions, on the same release.
The tools, grouped by what they answer
Three categories. None of them require a dedicated SDET anymore.
| Category | Examples | What they measure | Best fit |
|---|---|---|---|
| Coverage | JaCoCo, Istanbul, coverage.py, gcov | Statement and branch coverage during test runs | Every team running unit tests |
| Mutation testing | StrykerJS, PIT, Mutmut | Quality of the test suite itself | Teams that want to know if the tests are real |
| SAST and structural analysis | SonarQube, Semgrep, Snyk Code, GitHub CodeQL | Code-level defects without running the code | Anyone shipping auth, payment, or user data code |
Quick point to think about while we are here -
If you are paying for SonarQube and not running mutation testing, you are buying signal you do not need and skipping the signal you do. SonarQube tells you the code looks clean. Mutation testing tells you the tests work. Most teams have the budget reversed.
The coverage tools were always available. The barrier was not the tool. It was the time to act on what the tool surfaced. That barrier just dropped.
White box and black box are not alternatives
Let me show you why the alternatives framing falls apart in practice.
Most articles on white box testing treat it as a competing category to black box testing. Pick one based on what you know. That framing was always a simplification. Today, it is actively misleading.
| Question | White box | Black box |
|---|---|---|
| What does the tester see? | Source code, control flow, data flow | Inputs and outputs only |
| What does it prove? | Implementation covers every branch and path | System behaves correctly for the user |
| Where does it live? | Unit tests, coverage reports, mutation testing, SAST | E2E, integration, acceptance, regression |
| Who runs it? | Developers, peer reviewers, and AI agents reading source | QA engineers, AI agents driving the UI |
| What kind of bug does it catch? | Logic errors, untested branches, weak tests | Wrong behaviour, broken flows, missing features |
The two failure modes are independent. A function with 100% branch coverage can still ship a feature that does not do what the user expected. A passing E2E suite says nothing about an untested error-handling branch deep inside a function. Both blind spots can be present at once, on the same release, and most teams have only ever measured one.
Black box owns the E2E and regression surface. White box owns the unit and build-pipeline surface. A working QA program runs both.
What it catches, what it misses
White box catches bugs the user cannot reach. A code path reachable in principle but rare in usage will never be exercised by black box testing. White box exercises it because the code is there.
Feedback is fast. Failed test, you know the line, the branch, the condition. Coverage percentages, mutation scores, and SAST findings are all numeric and ratchetable release over release.
What it misses is also clear. A function with 100% branch coverage can still ship a feature that does not do what the user expected. Coverage proves you exercised the code, not that the code is right. This is the failure mode I find most teams underrate.
QA leads who report statement coverage in QBR slides are stalling for time. The number does not say what the executive thinks it says. It says the tests touched the code. It does not say the tests verified anything. If your leadership is making release decisions on that number, you have a metric problem dressed up as a quality program.
White box tests are also tied to implementation. Refactor and they break, even when the behaviour did not change. And when the implementation is wrong but matches the spec, white box tests pass on broken code. That is why white box pairs naturally with regression testing at the black box layer.
What changed in the last 18 months
Three shifts, briefly.
AI agents read source code well enough to generate the cases. The technique work hasn't changed. The labour of producing the test inputs collapsed.
Coverage analysis stopped being a luxury. JaCoCo and Istanbul and coverage.py were always available. The reports now get acted on automatically. Agents identify the gaps and propose tests.
The rationed techniques are now affordable. MC/DC, path coverage, mutation testing. The economic constraint that kept them in aerospace and finance for fifty years just stopped applying.
Across the customer onboardings Bug0's forward-deployed engineers have watched this year, the pattern is consistent. The white box discipline gets handled inside the AI coding loop, where the developer and the agent share ownership. The customer-side regression suite is where outsourced help compounds best, because that surface is where the bugs the user actually sees live.
If your team does not have the bandwidth to run both layers, the black box and E2E regression layer is the one to outsource first. That is what Bug0 owns end-to-end for growth-stage teams without a QA hire. Your white box discipline stays with your developers, where it belongs.
The teams that get this right stop treating coverage as a metric to hit and start treating it as a question to answer. What paths did we never exercise? That question gets cheaper to ask every quarter.
FAQs
What is white box testing in simple words?
White box testing is the practice of testing software by reading the source code and designing tests that exercise specific branches, paths, or conditions inside it. The tester has full access to the implementation. Synonyms include clear box, glass box, transparent box, and structural testing.
What are the main white box testing techniques?
Statement coverage, branch coverage, condition coverage, path coverage, and modified condition / decision coverage (MC/DC). Mutation testing is a related test-adequacy technique, not coverage, but it sits in the same toolkit because it answers a question the coverage measures cannot: whether your tests actually verify anything.
What is the difference between white box and black box testing?
White box testing evaluates the code itself: branches, paths, conditions, and the logic inside functions. Black box testing evaluates behaviour from the user's perspective, with no view of the implementation. They answer different questions, and most production systems need both. The companion piece on black box testing covers the user-facing layer.
Is white box testing the same as unit testing?
No, but they overlap heavily. Unit testing is a level: testing one function or class in isolation. White box testing is a methodology: testing with knowledge of the code. Most unit tests are white box, because the person writing them has read the code. White box techniques also apply at integration and system levels when you have access to the source.
What tools are used for white box testing?
Three categories. Coverage tools (JaCoCo for Java, Istanbul for JS/TS, coverage.py for Python). Mutation testing tools (StrykerJS for JS/TS, PIT for Java, Mutmut for Python). Static analysis tools (SonarQube, Semgrep, Snyk Code, GitHub CodeQL). All three have become routine for small teams as cost and friction dropped.
What is mutation testing, and is it white box?
Mutation testing introduces small changes called mutants into the source code and re-runs the test suite. If the tests still pass, the suite did not verify the behaviour. It is a white box technique because it requires access to the source, but it measures test quality rather than code coverage. StrykerJS, PIT, and Mutmut run it in CI today.
How does white box testing pair with regression testing?
They cover different failure modes. White box catches the logic bug inside a function. Black box regression catches the unintended side effect at the user-facing layer after a deploy. A working QA program runs both, on every release. If you are outsourcing one layer, the black box and E2E regression suite is usually the higher-leverage choice. That is what Bug0 covers for growth-stage teams at $2,500/month.



