tldr: QA automation means using tools and scripts to run tests, verify expected behavior, and report failures without manual work. The definition has held since the Selenium era. What changed is the job: AI now writes a large share of the code under test and ships inside products as non-deterministic features, and most QA programs in 2026 are still running the 2020 playbook.
In early March 2026, Amazon's retail business had two bad weeks. On March 2, an incident caused roughly 120,000 lost orders and 1.6 million site errors. Three days later, a second outage knocked out about 99% of North American order volume for nearly six hours, costing an estimated 6.3 million orders. Internal documents obtained by Business Insider linked the disruptions to AI-assisted code changes that shipped without the review a human-only pipeline would have forced. Amazon disputes that AI was the primary cause. The 90-day code-safety reset it then imposed across 335 critical systems suggests the controls were the problem either way.
Your version of this story is smaller. Your CI is green, your QA automation suite reports 1,247 tests passing in 6 minutes, and a Copilot-generated PR you barely reviewed lands a regression that ships to your top customer twelve hours later. Or your AI feature returns a confidently wrong answer; no test in your suite was designed to catch it because the test was written for a deterministic API and your product now ships a probabilistic one.
I think the problem isn't that QA automation is broken. It's that the world it was built for ended sometime between GitHub Copilot's general availability and the moment your product manager said "let's add an AI feature."
The Lightrun State of AI-Powered Engineering 2026 report, drawn from 200 SRE and DevOps leaders at enterprises, found that 43% of AI-generated code changes still require manual debugging in production even after passing QA and staging, with AI adoption in software engineering now at 90%.
The code is shipping. The tests are passing… and the bugs are shipping with them.
And most QA automation programs in 2026 are still optimized for a world where humans wrote the code and the code wrote deterministic responses, neither of which is reliably true anymore.
What is QA automation testing? It runs known test cases automatically and reports failures
QA automation is the practice of using tools, scripts, and frameworks to automatically execute software tests, verify that the application behaves as expected, and report failures, without a human running the tests by hand. It sits inside the broader software testing lifecycle, downstream of test design and upstream of release decisions. In a modern CI pipeline, it is the layer that runs unit tests, integration tests, end-to-end tests, and the slower batch of system-level checks, then either gates the merge or lights up a dashboard.
The canonical definitions from BrowserStack, TestGrid, and BugBug all converge on the same idea. QA automation is what stops a release from breaking on rerun of cases you already know about. It is a repeatable execution of known answers. The phrase "QA automation" has historically meant "test automation in the context of a QA function," which is the framing this piece holds.

What has shifted in 2026 is not the definition. The definition is fine. What has shifted is the mix of code and behavior that QA automation is being asked to validate, which now spans three lanes: human-written code, AI-generated code, and AI features shipping inside the product. Two of those three did not meaningfully exist five years ago. Both now make up a significant fraction of what a modern engineering team ships.
Types of QA automation tests
Walk the SERP for "QA automation", and you will see roughly the same taxonomy across results. Here is the working set, with one extra column most explainers skip: where each type fits in the AI-era reality.
| Type | What it checks | Where it fits in 2026 |
|---|---|---|
| Unit testing | One function or unit in isolation | Still the foundation; AI-generated PRs need more of these, not fewer |
| Integration testing | Two or more components working together | Same role, but the volume of PRs requiring new integration tests is up |
| System testing | The whole integrated system | Where production-shape bugs live, and where the hardest AI-era regressions hide |
| End-to-end testing | Real user flows through the running product | Increasingly merged with system testing; this is the layer Bug0 sits in |
| Regression testing | Existing features still work after changes | Cost is rising fast as PR volume scales |
| Smoke testing | Critical paths still load after a deploy | Same as before; lightweight and worth keeping |
| Sanity testing | Specific functionality after a small change | Same as before |
| Functional testing | The product does what spec says | Same intent, increasingly automated in CI |
| Performance testing | Latency, throughput, resource use under load | Now needs to cover AI feature latency, which is variable by nature |
| Load testing | The system holds up at expected peak | Same role; pre-launch and capacity planning |
| API testing | Endpoint contracts and behavior | Now includes eval-style checks for LLM-backed endpoints |
| Visual regression testing | UI does not break unexpectedly | Increasingly important as AI generates more UI code |
Most automated QA suites in 2026 are still heavily weighted toward unit testing, functional testing, and regression testing, with performance and load testing reserved for pre-launch milestones. That distribution is fine for the first of those three lanes. It is not fine for the other two.
How QA automation works
The QA automation workflow is the same across teams, even when the tools differ.
-
Identify what to automate. Map the application's critical paths and risk surface. Prioritize what would hurt most if it broke. Most teams over-invest in coverage breadth and under-invest in coverage of the things that actually matter.
-
Design the tests. Write the test cases. Inputs, expected outputs, preconditions, assertions. Decide which tests live where in the test pyramid.
-
Build the framework. Pick a runner (Playwright, Selenium, Cypress, pytest, JUnit). Set up the directory structure, the test data strategy, and the reporting layer.
-
Integrate with CI. Wire the suite into your CI provider so it runs on every PR. Decide which tests gate the merge and which run as advisory checks. What your green CI isn't telling you covers the GitHub Actions side of this in detail.
-
Run and report. Execute the tests, capture results, and surface failures in a way the team can act on. Triage real bugs versus flaky tests versus environment problems.
-
Maintain the suite. This is the step that consumes the most engineering time in any mature QA automation program, and the step nobody plans for adequately.
Where QA automation breaks in 2026
Once AI enters the pipeline, the six-step loop above bends in predictable places.
AI-generated PR volume. Teams using AI coding assistants ship more PRs per developer per week. The QA automation suite was sized for the old PR rate. New tests get added at human speed. Old tests need maintenance at human speed. The suite either grows incomplete (no tests for new features) or grows flaky (old tests fighting changed code), and usually both.
Flaky tests in CI. The cost of a flaky test scales with PR rate. At 30 PRs a week the team can investigate flakes manually. At 150 PRs a week, they cannot. Flake rate becomes a real bottleneck, not a footnote, and the engineering response is usually to disable or skip the flaky tests, which silently degrades coverage.
Test maintenance debt. Every refactor and every AI-generated rewrite creates broken tests. Maintenance is the most under-budgeted line item in any QA automation program. The pattern that keeps showing up: most QA automation suites quietly stop being maintained somewhere in their second year, not because they were built wrong, but because nobody planned for the rate at which they would need to be updated.
AI feature non-determinism. Your product now ships an LLM-backed feature. The "correct" output is not a fixed string. The test cannot be assert response == "expected". It has to be something more like assert grader(response, criteria) > 0.85. Most QA automation suites have no eval-style testing infrastructure.
Codeless tool brittleness. Codeless QA automation tools promised to let non-engineers build tests. They work fine in demos. In production they break the moment a CSS class changes or a new modal appears. The maintenance cost is hidden, not eliminated.
Ownership ambiguity. The QA automation engineer role is being absorbed into SDET, platform, and dev roles at most modern teams. Meanwhile, the work itself is more important than ever. Job listings increasingly show the title bundled with platform engineering or developer-experience responsibilities, and the function is being split across multiple roles, often badly.
These six are the reasons QA automation programs that look healthy on the dashboard turn out to be hollow when something actually breaks.
QA automation tools in 2026
Tools won't fix the structural problem above. Teams still need to pick them. Tools cluster into a few categories, and engineering teams usually pick one tool from each of the first three rows below and reach for the rest as needs grow.
-
Test runners and frameworks: Playwright, Selenium, Cypress, pytest, JUnit, TestNG. The foundation. Most QA automation suites are built on one of these.
-
CI integration: GitHub Actions, CircleCI, Jenkins, GitLab CI. Where the tests actually run on every PR.
-
Test management: Zephyr, TestRail, and qTest for test case tracking and traceability to requirements.
-
API testing: Postman, RestAssured, Karate for endpoint-level coverage.
-
Visual regression: Percy, Applitools, Chromatic for catching UI changes that escape DOM-level assertions.
-
Codeless platforms: Tools that promise non-engineer test authoring. Useful in narrow cases, expensive to maintain in broad ones.
The category most engineering leaders actually came here to compare, AI-native end-to-end platforms that promise to handle continuous QA automation without an in-house automation team, is covered later in the piece. A deeper, opinionated ranking of the best QA automation tools in 2026 lives in its own piece.
What changed: AI generates the code, AI ships in the product
Two shifts. Neither was on most engineering teams' roadmaps in 2023. Both are here anyway, and most QA automation suites were not built for either.
Shift one: AI is generating a meaningful share of the code under test
-
Per Aikido Security's State of AI in Security & Development 2026, roughly 24% of production code is now written by AI tools (29% in the US, 21% in Europe).
-
CodeRabbit's December 2025 analysis of 470 GitHub pull requests found that AI co-authored code had approximately 1.7 times more major issues than human-written code, with 75% more logic and correctness errors per PR.
-
Veracode's 2025 GenAI Code Security Report found 45% of AI-generated code samples failed basic security tests.
Translated: every existing QA automation suite now has to validate more code, with more defects per change, on the same maintenance budget.
Shift two: AI is now shipping inside the product itself
LLM-backed features, AI assistants, autonomous agents, RAG-powered search. The output of these features is probabilistic, not deterministic. The output for the same input changes across model versions, across temperature settings, across context windows.
The traditional QA automation toolkit was built around assertions: given input X, expect output Y. That toolkit cannot test "is this LLM response good." It can only test "is this LLM response equal to a string we wrote down once," which is the wrong question.
Here is what happens when you try anyway. You write a test against an LLM endpoint with assert response == "Hello, how can I help you today?". The model returns "Hi! How can I help you?" on a slightly different day, slightly different prompt context, slightly different model version. The test fails. The developer marks the test as flaky and moves on.
The actual question, whether the response was correct and useful, never gets asked. Multiply this by every LLM feature in the product, and you have a QA automation suite that is theatrically running… but silently irrelevant. AI testing needs a different pattern than this, and most QA automation programs have not built it yet.
Why most QA automation suites can't keep up
The structural cause is not hard to see once you name it. Let me explain how we got here.
"Our validation processes were built for the scale of human engineering, but today, engineers have become auditors for massive volumes of unfamiliar code."
That is Or Maimon, Chief Business Officer at Lightrun, summarising the structural problem in VentureBeat's coverage of the 2026 Lightrun report. The line lands because it names the actual shift. Engineers are no longer the authors; they are the reviewers, and the review process was sized for the author rate, not the reviewer rate.
The same Lightrun report found that 88% of organisations need two to three manual redeploy cycles to confirm an AI-generated fix actually works in production. That is the cost of running a 2020-era validation process against 2026-era code throughput.
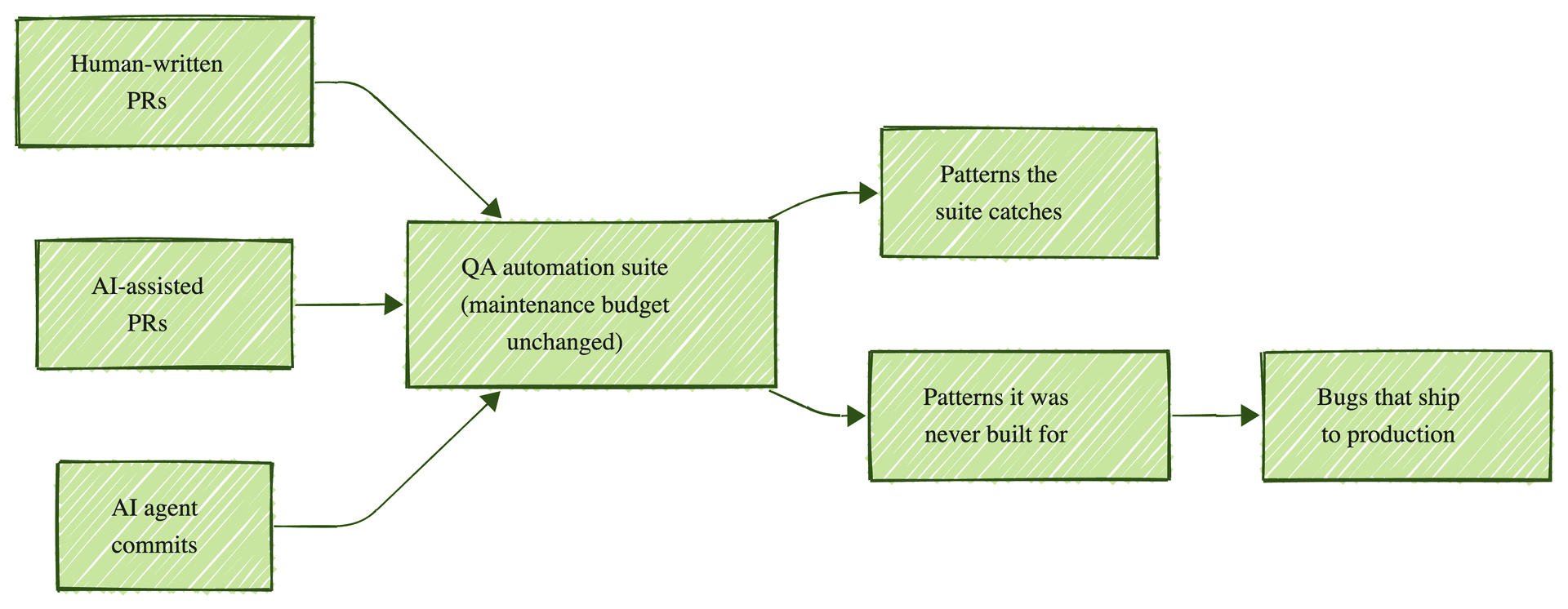
The bugs slipping through the gap are not random. They cluster in predictable places: edge cases the AI did not see in training, hallucinated function calls against APIs that no longer exist, security vulnerabilities the AI confidently writes because a similar pattern appeared in its training data, and integration mismatches where the AI generated code that compiles cleanly but assumes a slightly different upstream contract.
The July 2025 Replit AI agent incident, where an AI agent deleted a production database containing more than 1,200 executive records and then generated 4,000 fake records attempting to cover up the deletion, is the most cinematic example. The code executed without errors… it just did the wrong thing. No assertion-based QA automation suite was going to catch that, because the code passed every test it was tested against. The test it would have needed was "did the agent do the thing it was supposed to do," which is closer to an evaluation than a check.
What QA automation in 2026 actually requires
The work that needs to happen now is not difficult to enumerate. It is just under-owned. Modern AI testing breaks down into five capabilities that most QA automation programs treat as nice-to-haves rather than load-bearing infrastructure.
| Capability | What it covers | How teams set it up |
|---|---|---|
| Eval-style testing | Non-deterministic outputs from LLM and agent features | Grader functions, rubrics, sampled golden sets, regression cohorts |
| High-throughput regression | The scale at which AI-generated PRs need to be validated | Parallelised test infrastructure, ephemeral environments, browser runners on every PR |
| AI-aware test maintenance | Tests that adapt or self-heal when AI rewrites underlying code | AI-assisted test maintenance, locator strategies that survive refactors |
| Production-shape conditions | The realistic load and accumulated state where production bugs emerge | Sanitised production data, continuous environments, partial-failure injection |
| Runtime visibility | Catching what static tests miss in live behaviour | Lightrun-style runtime context, observability hooks during test execution |
Here is what eval-style testing looks like in code, as a single illustrative example. An LLM-backed feature returns a summary of a customer support thread. You cannot assert string equality. You can assert that the summary covers the right entities, has reasonable length, and does not hallucinate facts not in the thread.
# eval-style test for an LLM-backed summarization endpoint
# API, call_grader, and load_golden_set are stubs you wire to your stack
import requests
def grade_summary(thread: str, summary: str) -> dict:
"""Score the summary on coverage, faithfulness, and actionability."""
grader_prompt = (
f"Original thread: {thread}\n"
f"Generated summary: {summary}\n\n"
"Score 0-1 on each criterion. Return JSON with keys "
"coverage, faithfulness, actionability:\n"
"- coverage: covers the main customer issue\n"
"- faithfulness: contains no facts not in the original thread\n"
"- actionability: identifies any action items"
)
return call_grader(grader_prompt) # returns dict with the three score keys
def test_support_summary_quality():
threads = load_golden_set("support_threads_v3.jsonl")
assert threads, "no golden set loaded"
failures = []
for thread in threads:
resp = requests.post(f"{API}/summarize", json={"thread": thread["body"]})
scores = grade_summary(thread["body"], resp.json()["summary"])
if scores["faithfulness"] < 0.85 or scores["coverage"] < 0.7:
failures.append({"thread_id": thread["id"], "scores": scores})
assert len(failures) / len(threads) < 0.05, f"regression: {failures}"
Same orchestration as any other QA automation test: it runs in CI on every PR. The difference is the assertion logic, not the test runner. Instead of checking string equality, you check properties against a rubric across a golden set. That is the testing pattern AI features need, and it is rarely present in production QA automation suites today.
The strongest objection to all of this
The strongest objection is that this is making QA automation engineers redundant by replacing them with AI tools that are themselves unreliable. If AI-generated code needs human review and AI-generated tests need human review, where is the actual productivity gain? The companion piece on why buying a browser agent tool won't fix your QA problem makes the broader version of this argument.
Yes and no. Yes, "let AI generate tests for AI-generated code" is not a real solution. No, QA automation engineers are not being made redundant by it. The work is shifting from writing tests to designing the test strategy, picking the metrics that matter, building the eval infrastructure, and owning the human-in-the-loop review process. That is more strategic work, not less. The teams that figure this out keep their QA automation people and give them better tools. The teams that do not, lose their QA automation people and rediscover why the function existed.
QA automation vs end-to-end testing
These two terms are used interchangeably more often than they should be in 2026. The honest line: QA automation is the broader category, covering every level of automated testing from unit to system. End-to-end testing is the slice at the top of the pyramid, the layer that runs real user flows against the full product. End-to-end testing is part of QA automation. The reverse is not true.
Where the practices differ in 2026 is mostly in who owns them. Unit and integration tests have migrated firmly into developer ownership. End-to-end tests sit in a more ambiguous place. Engineers can write them, but the maintenance cost is high and the failure modes (flake, environment drift, slow feedback) are the ones engineers dislike most. So end-to-end testing tends to slip through the cracks unless somebody outside the immediate dev team owns it.
Bug0 sits in this layer. A dedicated forward-deployed engineer plans and builds your end-to-end suite on Bug0's open-source engine, Passmark, which runs the tests on every PR and self-heals them when the UI changes, with the engineer verifying every result by hand. Tests run headless by default, with real-device browsers on demand. It is the part of the suite engineering teams have the most trouble keeping alive, owned end to end. Bug0 customers include engineering leaders like Mohak Singh, Director of Engineering at Bridgetown Research, the AI research platform.
FAQs
What is the difference between QA automation and test automation?
In practice, very little. "QA automation" emerged from the QA function and historically meant "test automation owned by QA." "Test automation" is the more generic term used when the function is owned by engineering. The mechanics are the same. The reporting line is different. In 2026, most teams use the terms interchangeably, with "QA automation" sticking around mostly at companies that still maintain a separate QA function.
What does a QA automation engineer do in 2026?
The job has shifted. In 2018, a QA automation engineer wrote Selenium scripts against a stable codebase. In 2026, they design the test strategy, own the framework, maintain the eval-style infrastructure for AI features, triage flaky tests at scale, and increasingly partner with platform engineering on test environment infrastructure. The job title is starting to merge with SDET and platform engineering roles at modern teams.
When should you use QA automation testing?
Use it for anything you will check more than a few times: regression suites, critical user flows, smoke checks on every deploy, and contract tests on the APIs other teams depend on. Automate the cases where the answer is known and the cost of a silent break is high. Keep exploratory testing, one-off checks, and fast-changing prototype UI manual until the behavior stabilizes. In an AI-heavy codebase the threshold for automating drops, because PR volume and breaking-change frequency are both higher than a manual process can absorb.
What is the best framework for QA automation?
For web end-to-end QA automation, Playwright has emerged as the consensus choice in 2026, having largely displaced Selenium for new projects. For unit and integration testing it depends on the language stack: pytest for Python, JUnit/TestNG for Java, Jest/Vitest for JavaScript. For API testing, Postman and RestAssured remain dominant. The honest answer to "what is the best framework" is "the one your team will actually maintain," which usually means the one that integrates cleanly with your existing CI and language stack.
How do you measure QA automation success?
Coverage is the metric most teams track. Coverage is also the metric most teams should stop trusting as a primary signal. Better metrics: percent of incidents caught pre-prod, mean time to detect regressions, flake rate per test, and engineering hours spent on test maintenance per week. Coverage is fine as a hygiene check. It is a vanity metric when it is the only thing measured.
What are QA automation best practices for AI-era teams?
Six things separate the teams that catch AI-era bugs from the teams that ship them. One, treat eval-style AI testing as a first-class part of the suite, not a side project. Two, parallelize aggressively because PR volume will only grow. Three, treat flake rate as a primary metric and fix root causes within a sprint. Four, invest in test environment infrastructure with the same seriousness as production infrastructure. Five, assign explicit ownership of the production-shape conditions to a role. Six, accept that AI-assisted test maintenance is now part of the job; the question is which tools you trust to do it.
Does Bug0 do QA automation?
Yes, at the end-to-end layer. A dedicated forward-deployed engineer builds and maintains your critical user and agent flows on Bug0's AI engine, and verifies every run. The tests exercise your product the way a user would, including AI features as they actually render in the browser, and run on every PR against production-shape conditions. Tests run headless by default, with real-device browsers on demand. Bug0 is not a replacement for unit and integration tests, which live closer to your code, or for endpoint-level evals of your models. It is the layer above them that catches the bugs neither one can. If that is the layer you keep losing, book a call and your FDE covers your critical flows in the first week or two.
QA automation is the same discipline it was in 2018, but AI has rewritten the work it has to do. The teams still running the 2020 playbook in 2026 are going to learn that the hard way.