tldr: AI writes code that looks right everywhere and is wrong in a few specific places. Test for that failure profile, not the generic one.
Your codebase is half AI-generated now. The other half is shoulder-surfed completions a human mostly trusted. The test infrastructure you have was designed for a different world, one where every function had a human author who knew what they meant to write and how to verify it.
That assumption is broken. Generative AI in software testing has not kept pace with either the volume or the failure profile of AI-written code, and the gap is where most production incidents now occur. The failure profile is the whole point of this piece. AI code fails in predictable places, and the playbook that follows organizes around those places.
You test AI-generated code by verifying behavior end-to-end, prioritizing by the failure profile: full user journeys first, then error and empty states, then the boundaries the AI guessed at, then the existing flows that touch the changed code. Unit tests and static analysis come after.
How AI-generated code fails differently
AI-generated code is not random. It has a specific failure profile that human-written code does not have.
It is confidently plausible everywhere. The function name is right. The imports are sensible. The parameters look correct. The structure mirrors every other function in your codebase. A reviewer scanning the diff sees nothing alarming.
It is mostly correct. The happy path runs. The unit test the AI also wrote passes. Static analysis is clean. The linter is clean.
Then it goes silently wrong, and not randomly. Across roughly 120 AI-built flows our forward-deployed engineers verified for one AI-native platform over a quarter, about 70% of the bugs that reached a pull request fell into the same three patterns.
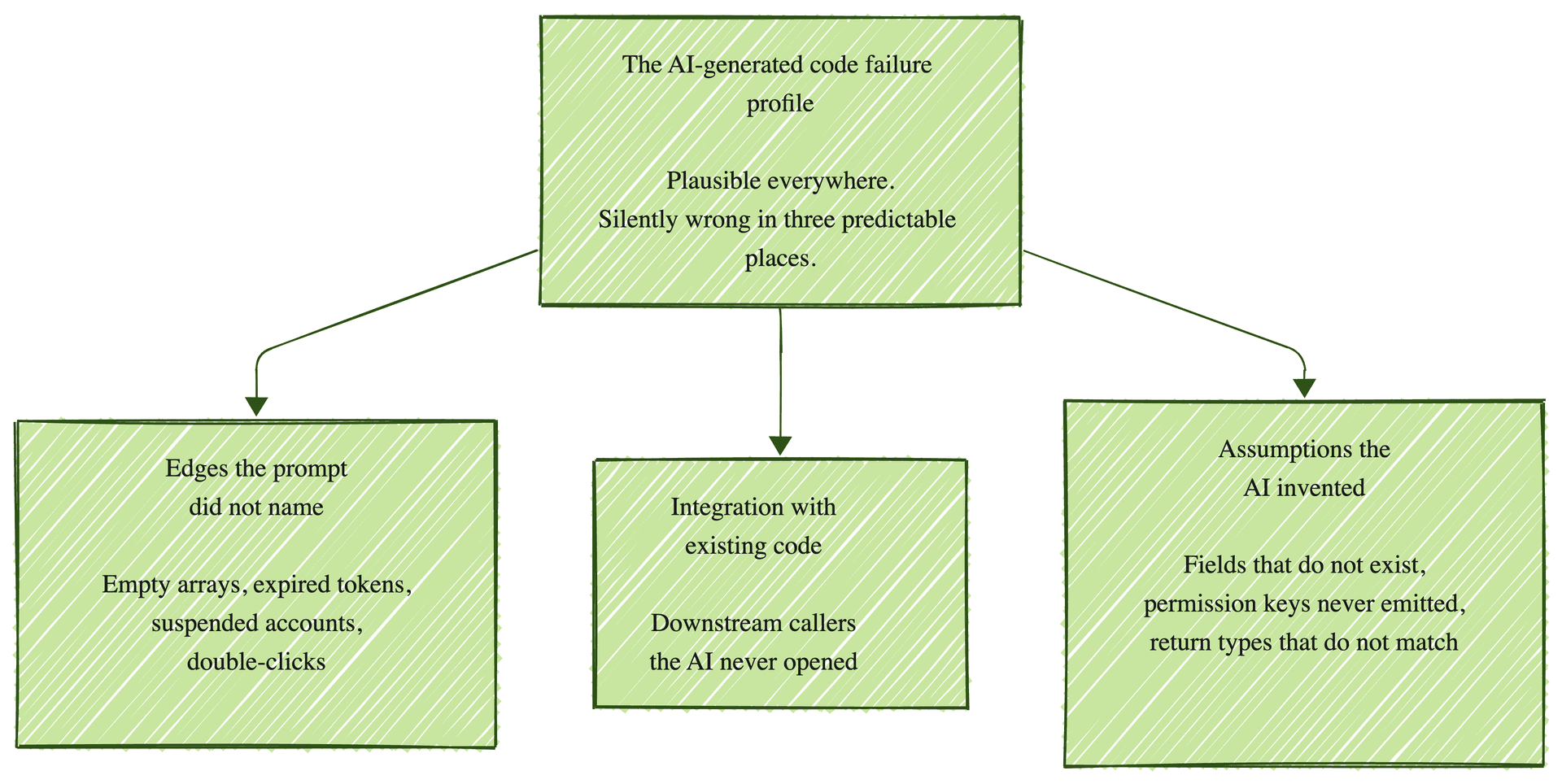
Edges the prompt did not name (about 45% of those): The AI built for the case the prompt described. Empty arrays, null arguments, expired tokens, the user clicking the same button twice: none of this gets written. If the prompt did not name the empty state, the empty state does not exist in the output.
Integration with code that already exists (about 30%): The AI sees the function you asked it to change. It does not always see the three other functions that import that function. A signature change updates the prompt's target and silently breaks downstream callers the AI never opened.
Assumptions the AI invented (about 25%): The AI made up an API field that does not exist, called a library function that returns differently than the AI thought, or used a permission key your auth system never emits. The code compiles. The function runs. The downstream behavior is wrong because the input assumption was hallucinated.
Let me show you what the third one looks like in practice.
// AI-generated. Looks correct. customer.tier does not
// exist on this model in production.
function isEligibleForDiscount(customer: Customer): boolean {
return customer.tier === 'premium' && customer.activeSubscription;
}
// Runtime: customer.tier is undefined for every user.
// Return value is false for every customer.
// No error thrown. Discount silently never applies.
The function compiles. The unit test the AI wrote against a mocked customer passes. The bug only surfaces when a real user hits a real discount flow against the real customer model. By then, it has shipped.
What to verify first when you test AI-generated code
Most teams test AI-generated code with the same priority list they used for human code: unit tests first, integration tests if there is time, end-to-end tests if the QA team forces it. That order is backwards for AI code.
The failure profile dictates a different priority. Let me put the priorities on the page.
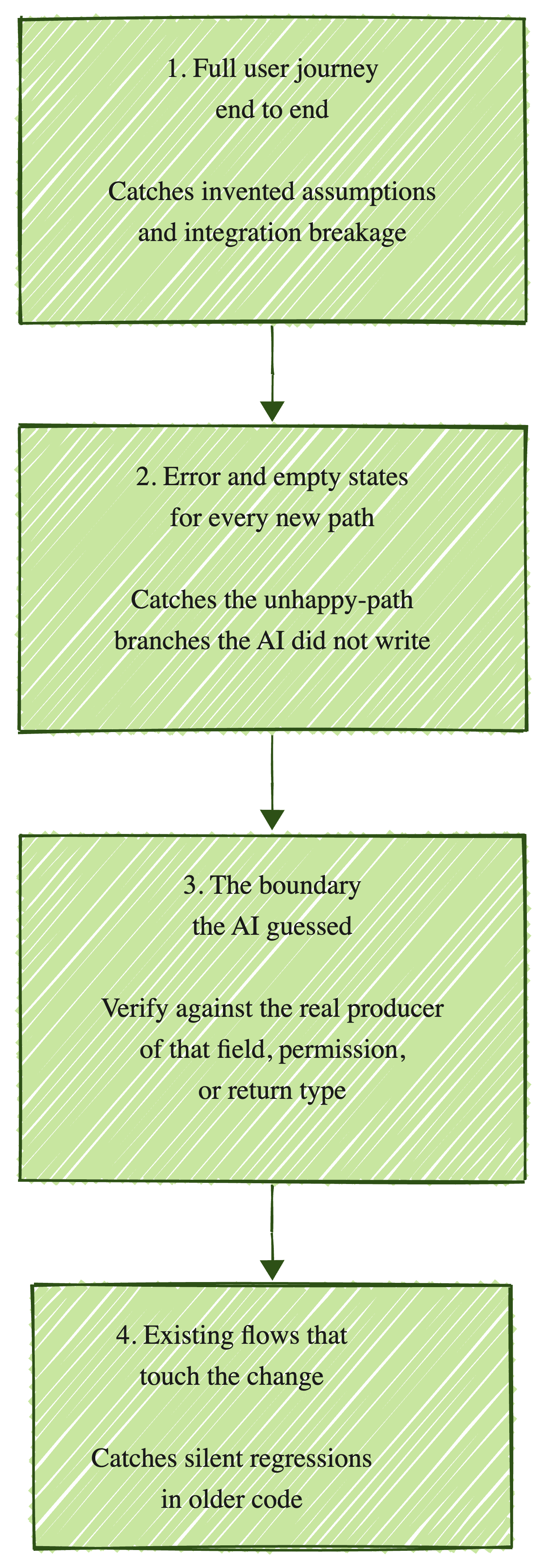
1. The full flow the feature touches, end to end: The AI built one function. Your customer uses a journey. Run the journey in a real browser, with realistic data, against the actual API surface. This catches the invented-assumption failures and the integration breakage. Unit tests catch neither.
2. Error and empty states for every new path: AI rarely writes the unhappy-path branches because the prompt rarely names them. Confirm that the empty list, the 500 response, the suspended account, and the rate-limited third party each produce the correct user-facing behavior.
3. The boundary the AI guessed: Find the spot where the AI made an assumption: a field, a permission, a return type, a status code. Verify it against the real producer of that data. Sometimes the producer is your own API. Sometimes it is Stripe. Sometimes it is Auth0 or a feature flag system that emits different keys than the AI assumed.
4. Existing flows that touch the changed code: Map the call graph or have something map it for you. Run the older flows that import the function the AI just changed. Silent regressions live here.
Unit tests and static analysis come after these four. They catch a thin slice of the failure profile. The time spent on them mostly feeds back to the AI rather than adding coverage.
A verification workflow that keeps up with generative AI in software testing
Generation got cheap. AI writes several times the code per engineer-hour it could 18 months ago. Verification did not get cheap at the same rate, and the mismatch is where the bottleneck sits.
The workflow has to invert the old cadence. Verification used to be a phase at the end of a sprint. Now it has to run on every change the AI ships.
What that looks like in practice:
Every push runs the end-to-end suite: Actual user journeys, in a real browser, against realistic data, executing on every change. The CI pipeline waits for them before letting the merge happen. Unit tests stay in their lane; they do not substitute for journey verification.
The suite covers the failure profile, beyond just the happy path: Empty states, error states, auth edges, and third-party degradation. Each of these is a test the AI did not write for itself.
Human review on every failure: AI cannot tell a flake from a real regression with the confidence a production release demands. A person looks at every red run, decides whether to ship, file, or rerun, and signs off.
The suite stays cheap to update: When the UI moves, the suite resolves to the new element through self-healing. When a flow changes shape, the test author updates the suite in plain language. Selectors stay out of it. The same AI volume that ships features helps maintain the tests.
The cadence is straightforward. The hard part is the cost. End-to-end on every push used to mean a 90-minute CI queue. With parallel execution and an AI runtime, the same suite runs in 5 minutes. That changes what is affordable.
Where AI testing still needs a human owner
Verification can run on every change. The pipeline can be cheap. The AI can generate the test code, run the suite, and cluster the failures by root cause. What it cannot do is decide that a release is safe to ship.
Someone has to look at the verification output and make the call. The call has stakes. If the call is wrong, production goes down, customers churn, and an engineer wakes up at 11 PM. AI does not have a name on the on-call calendar. The runtime is what we automated, and the accountability stayed with the engineer.
Let me show you how Bug0 runs that split:
A forward-deployed engineer plans coverage on your app and builds the suite on Passmark, our open-source Playwright-based AI engine. The AI engine takes over from there: it runs the suite in CI on every change, self-heals when the UI moves, and clusters failures by root cause. The engineer comes back at the end and verifies every failure before it reaches your team.
The engineer's name is on the verification call. Critical flows go live in 1 to 2 weeks. Pricing starts from $2,500 per month, flat.
If a managed model is not your shape, the structure still applies. Hire a strong QA engineer or SDET. Give them a credible AI testing tool. Have them own the verification call. The pattern that does not work, especially with AI-generated code, is letting the same loop that wrote the feature also decide whether the feature should ship.
We covered the broader argument in why a browser-agent tool alone will not fix QA.
FAQs
How do you test AI-generated code?
You test AI-generated code by verifying behavior end-to-end, prioritized by the failure profile. The order: full user journeys first, then error and empty states, then the boundaries the AI guessed at, then the existing flows that touch the changed code. Unit tests and static analysis catch a small slice and come after the four above.
Is AI-generated code reliable?
AI-generated code is reliable for the path the prompt described and unreliable for the paths the prompt did not. The Stack Overflow 2025 Developer Survey found trust in AI accuracy has fallen to 29%, down from 40% in 2024, and 66% of developers name "AI solutions that are almost right, but not quite" as their top frustration. That trust gap is the gap verification has to close.
What does AI-generated code get wrong most often?
AI-generated code gets edges, integrations, and invented assumptions wrong most often. Edges: empty arrays, expired tokens, suspended accounts. Integrations: the downstream callers the AI never opened. Invented assumptions: API fields that do not exist, return types that do not match, permission keys that the auth system never emits.
Can AI test its own code?
AI can generate test code, and it cannot reliably decide whether its own output is correct. The same blind spots that produced the bug (the invented assumption, the unnamed edge) produce a test that confirms the bug works. A human verifier still owns the call on correctness.
Do you still need humans to test AI code?
Yes, for two reasons. AI cannot reliably tell a flake from a real regression at the confidence level a production release demands. And AI tools do not have a name on the on-call rotation, so no model is accountable when production breaks. Humans own the verification call and the outcome.
How does Bug0 verify AI-generated features?
A forward-deployed engineer from Bug0 plans coverage for your app and builds the suite on Passmark, our open-source Playwright-based AI engine. The AI engine runs the suite in CI on every change, self-heals when the UI moves, and clusters failures by root cause. The engineer verifies every failure before it reaches your team. Critical flows are covered in 1 to 2 weeks; pricing starts from $2,500 per month, flat.
The codebase that is half AI-generated today will only tilt further that way. The teams that keep up are the ones who built verification that runs at AI speed before the AI volume hits them. The failure profile is the leading indicator. Catch it upstream, and the release calendar stops drawing blood.