tldr: AI code review checks that the code looks right. It does not check that your product works. Those are different jobs, and one of them happens after the merge.
In March 2026, after a string of outages, Amazon started mandating more code review on production changes, with even senior engineers now needing sign-off, reported by CNBC. Internal documents tied the trend to "GenAI-assisted changes" with "high blast radius." Amazon disputes that AI caused the outages, and says none of the incidents involved AI-written code. That argument will run for a while. The outages are not in dispute. For about six hours, users could not check out, see prices, or reach their accounts.
Notice the response, though. Faced with bad changes reaching production, Amazon reached for the most familiar lever there is: more review. Add a sign-off step. Mandate AI code review on every diff. That instinct is everywhere in 2026, and it is worth pulling apart.
Around the same time, AI code review had a moment. Anthropic launched Claude Code Review, a multi-agent reviewer that walks every pull request. CodeRabbit, Qodo, Greptile, and Macroscope all shipped updates. The message across all of them was the same: AI can now read your diffs and catch bugs before a human does.
So if you just rolled out AI code review, or you are deciding whether to make it mandatory, you have probably told yourself a comforting story. We have AI code review now, so an Amazon-style outage will not happen to us.
I want to push back on that. Review and testing are two different jobs. More review is real progress at one layer, and it leaves the layer that catches user-facing bugs untouched.
What does AI code review actually catch?
Give review its credit. I've spent some time at Bito, working on its AI code review tool, and I tried most of the competing ones while I was there. So this is not a drive-by opinion. The category is good at what it does, and it has only gotten sharper in the last six months.
AI code review tools post inline comments on every pull request. They run static analysis and security scanners in sandboxes. That is the AI code security layer: secrets in commits, SQL injection patterns, missing null checks, and the function someone copy-pasted from Stack Overflow without reading the license.
Claude Code Review dispatches parallel agents that walk the diff with full repository context, then ranks the findings and posts them inline.
Senior engineers do the same thing with their eyes. They catch the variable name that lies, the comment that drifted from the code, the test someone disabled instead of fixing.
Across all of these reviewers, AI or human, let me show you what the category reliably catches:
-
Style violations and convention drift.
-
Bugs visible in the diff. Null derefs, type mismatches, and missing awaits.
-
Security smells. Hardcoded keys, unsafe regex, injection patterns.
-
Dead code, unreachable branches, redundant work.
-
Documentation that no longer matches the implementation.
You should use these tools. Most teams are shipping more safely in 2026 with AI code review than without it.
The question is whether catching all of that is the same as covering the surface that breaks in production.
It is not.
What does AI code review miss?
AI code review misses any defect that only appears when the application runs as a whole, because the diff is text and the bug is timing. Let me give you four categories where this gets expensive.
Behavior across a full user flow:
A signup journey touches the auth service, the email service, the database, the dashboard, and the welcome modal. A pull request changes one line in auth. Review reads that line and approves it, because the line is correct.
The bug shows up two services downstream, where the dashboard now sends signed-in users to a 404 instead of their home page.
The diff is clean. The behavior is broken.

Regressions in features the PR did not touch:
AI-generated changes love to refactor adjacent code. A method gets a small rename. The reviewer approves it because the rename is internally consistent.
Three weeks later, a scheduled job that called the old method name fails silently in production. Nobody opened a PR on that job. Nobody flagged it in review. The behavior just stopped.
Integration and state:
Single-page apps carry state across routes. Payment forms carry tokens across modals. A change that looks correct in isolation breaks when a real user moves through the app with live session data.
Review sees the change. It does not see the journey.
Anything that only appears at runtime:
Race conditions. Cache invalidation. Third-party API responses that look fine in the docs and arrive differently in production.
The diff has none of this. It sits outside the surface review can read.
The most honest version of this point did not come from a vendor. It came from Anthropic, writing about a regression in their own Claude Code product in their April 23 postmortem:
"The changes it introduced made it past multiple human and automated code reviews, as well as unit tests, end-to-end tests, automated verification, and dogfooding. Combined with this only happening in a corner case (stale sessions) and the difficulty of reproducing the issue, it took us over a week to discover and confirm the root cause."
Read that one phrase again: made it past multiple human and automated code reviews.
This is the team that ships Claude Code Review, describing a bug that slipped past their own review tooling and the tests around it. The full picture only came together a week later.
Even when both layers are present and well-staffed, the runtime surface is large enough to swallow a bug. Betting everything on one layer is how teams get hurt.
Why "mandate review" feels safe and isn't
Mandating more review is the most defensible answer to an outage. Nobody got fired for adding a review step. It looks like governance.
Then you do the arithmetic.
Review effort scales with lines changed. Risk scales with behavior shipped. Those two curves are not on the same axis.
When AI writes more code, the number of lines changed goes up linearly. The behavior surface, meaning the number of paths a user can take through your product that could break, goes up combinatorially. Ship three times more code and you are closer to ten times more risk, because every new path interacts with every existing one.
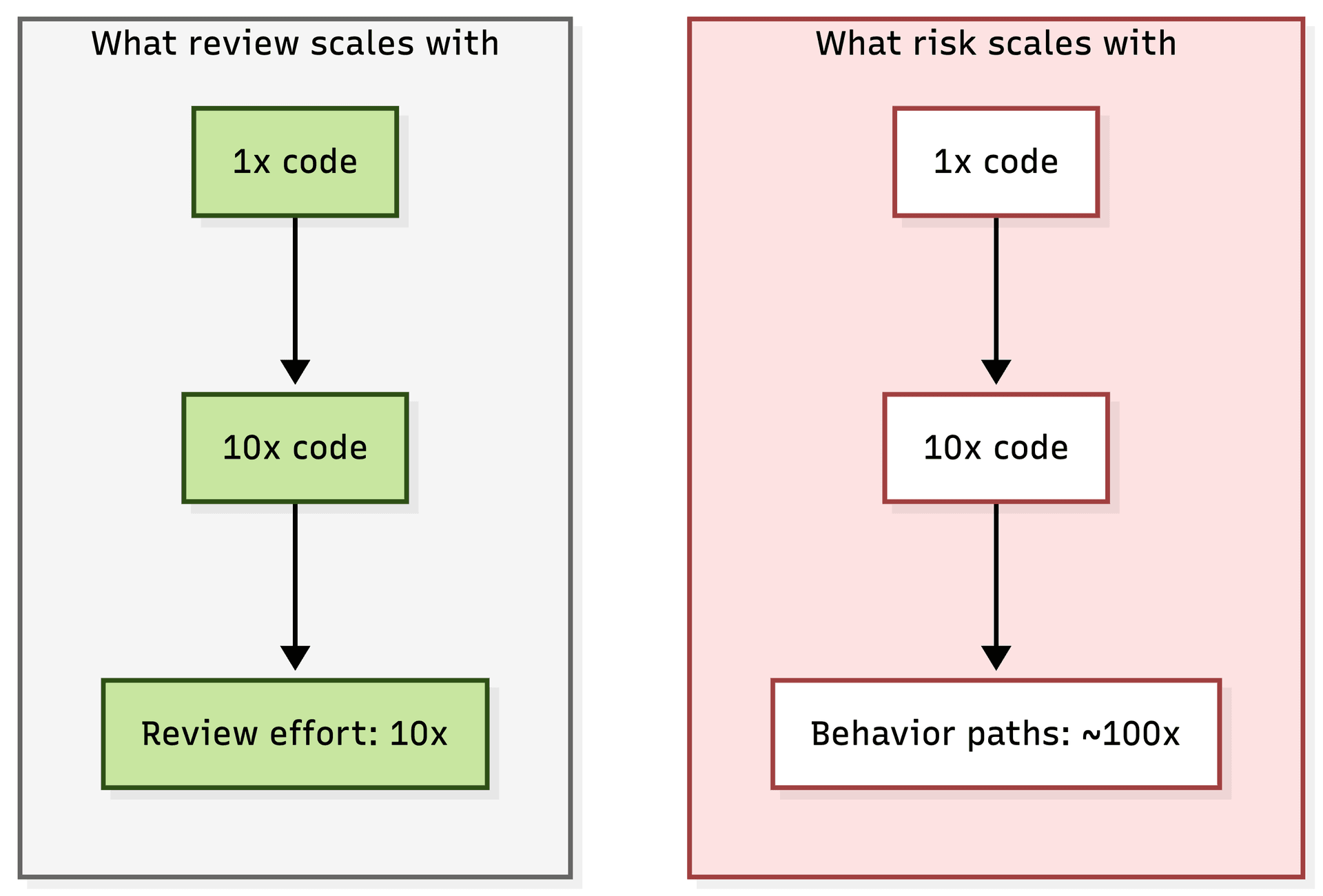
Senior sign-off slows the cadence. It does not change what the review can see.
The gap widens as AI writes more code, because the layer review covers shrinks as a share of what actually ships.
The fix has to live somewhere else.
The two layers, and what each is for
Code review answers a structural question. Does this change look right? Does it match conventions, keep secrets out of the repo, and stay readable for the next engineer?
End-to-end testing answers a behavioral question. Does the product work? Can a user sign up, pay, get a receipt, log back in tomorrow, reset a password, and cancel a subscription?
Both layers are necessary. Neither one substitutes for the other.
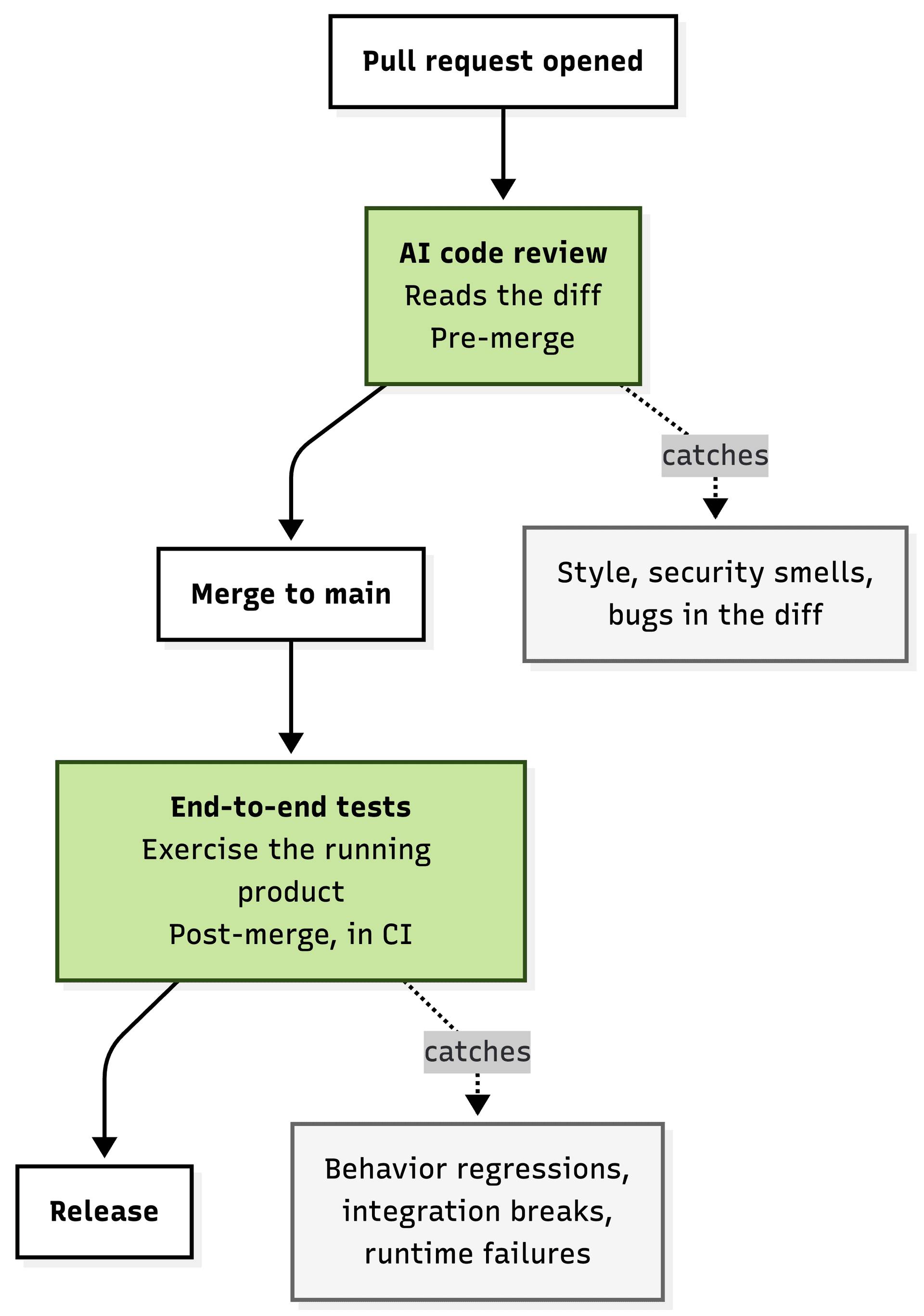
The same split in a table:
| Layer | What it sees | When it runs | What you lose if you skip it |
|---|---|---|---|
| AI code review | The diff | Pre-merge | Style, obvious bugs, security smells in the changed lines |
| End-to-end testing | The running product | Post-merge, in CI | Behavior regressions, integration breaks, runtime failures |
Most teams already have the first layer in good shape. They have Git, they have PR review, and many now have AI code review reading every diff. The second layer is where the exposure sits, and it is the harder one to staff. The E2E suite is flaky, the QA hire is six months from full coverage, and the team writes tests when they can, which is to say almost never.
That gap is wider than it used to be. AI made writing code three times faster, but on its own, it did nothing to make verifying behavior faster. So the code piles up faster while the layer that checks it stays stuck.
So here is a model that closes that gap without asking your team to write the tests themselves.
This is the model Bug0 uses, and it starts with a person. A forward-deployed engineer joins your sprint, learns your product, and writes the end-to-end flows that cover your critical paths. Those flows run on Passmark, the open-source AI regression engine underneath it. The AI runs them on every PR and repairs them when your UI shifts, so a moved button does not break the suite. When something real breaks, the same engineer verifies it, files the bug, and gates the release.
The engineer is the author. The AI is the engine. Your team never writes a test.
The flows live in a GitHub repo you share with your engineer, and they run on Passmark, which is open source. So they stay yours even if the engagement ends. You can clone the repo and run them on self-hosted Passmark with your own API keys. That matters more than it sounds: behavior coverage you cannot take with you is coverage you are renting. Legora, one of Bug0's customers, runs its critical flows this way, and pricing starts at $2,500 a month.
You end up running both layers side by side, and they cover different things. One tells you whether the change is sane. The other tells you whether the product still works.
FAQs
Is AI code review enough on its own?
No. AI code review verifies the diff at the moment a change is proposed, while behavior is what the product does at runtime once that change merges with everything else. A pull request can pass review and still break a downstream flow, because review reads code and behavior gets exercised by a real user. Use AI code review for the diff layer, and end-to-end tests for what only shows up at runtime.
What does AI code review miss?
AI code review misses any failure that only appears when the application runs as a whole, including cross-service flows, integration state, race conditions, third-party API behavior, and regressions in features the PR never touched. Tools like CodeRabbit and Claude Code Review catch style violations, security smells, and bugs visible in the patch. The runtime layer needs end-to-end testing on top of that.
Why is Amazon mandating AI code review?
Amazon is not mandating AI code review tools specifically. After a string of outages it began requiring extra human sign-off on production changes, even from senior engineers, and internal documents tied the trend to "GenAI-assisted changes." That is the same instinct most teams have, and it does not touch the behavior layer. Amazon disputes that AI caused the outages and says no AI-written code was involved. The confirmed root causes, like misconfigured access and wide blast radius, are not the kind of thing a diff review catches anyway. Catching a problem in review is a different job from catching it in the running product.
What is the difference between code review and end-to-end testing?
Code review inspects the diff at the moment a change is proposed. End-to-end testing inspects the running product after the change merges, by exercising the full user journey. Review catches style, obvious bugs, and security issues in the patch. End-to-end testing catches regressions, integration failures, and runtime behavior the patch alone cannot reveal.
How does Bug0 verify behavior after review?
A forward-deployed engineer authors end-to-end flows on Passmark, the AI runs and self-heals them on every PR, and the engineer verifies every failure before the release ships. The engineer is the author and the verifier; the AI is the engine. That puts a behavior-layer check after the merge, where code review cannot reach.
Run both layers and they carry their share. Bet everything on review, and you keep finding out in production what the diff could not see. The bugs live one layer below review. If you want to see what that layer looks like in practice, book a call.